7.2.6. Example: Small Language Model (SLM) Supervised Fine-Tuning (SFT)
This example demonstrates how to perform supervised fine-tuning (SFT) of a Small Language Model (SLM) using an MN-Core2 device with MLSDK. Supervised fine-tuning adapts a pre-trained SLM to a specific task or dataset by training it on labeled data.
7.2.6.1. Training Flow
The training script, slm_sft.py, implements the SLM SFT workflow.
The core logic is implemented in the run_with_py_gradient_accumulation() function.
The workflow consists of the following key steps:
Preparation: Set up the
MNCore2execution context and initialize thetokenizer.Model Loading: Load a pre-trained SLM. The script maintains two copies of the model: one on the MN-Core2 device (
model) for forward and backward computation, and another on the host (model_copy_on_cpu) for parameter updates.Compilation: Compile MN-Core2 kernels for training (
calc_grad_and_loss) and evaluation (eval).Data Preparation: Load and preprocess the dataset used for fine-tuning.
Training Loop: Iterate over the dataset, performing forward and backward passes to compute gradients and update model parameters.
Evaluation: Run evaluation on MN-Core2 and validate training and evaluation losses against predefined thresholds.
Model Saving: Optionally save the fine-tuned model to disk.
7.2.6.2. Training Loop Iteration
During each iteration of the training loop, a batch of training samples is loaded.
Each sample in the batch is processed individually on the MN-Core2 device to compute the loss and gradients using the compiled calc_grad_and_loss kernel.
After each sample is processed, the loss value is transferred to the host and accumulated. Once all samples in the batch have been processed, the accumulated gradients are transferred to the host and used by a host-side optimizer to update the model parameters.
The following figure illustrates the data and execution flow for a single training loop iteration in the SLM SFT process.
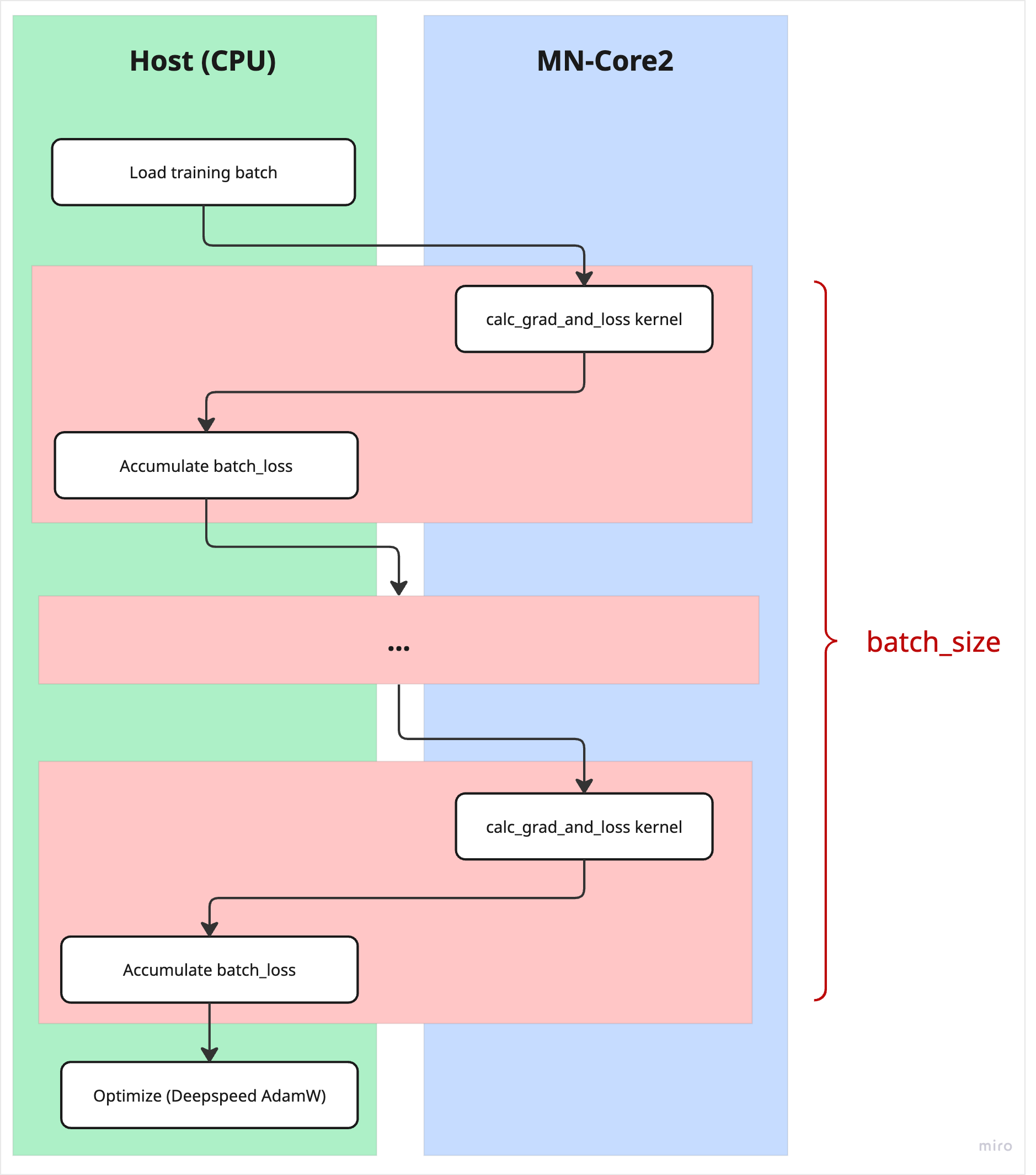
Fig. 7.6 Training Loop Iteration Flow
7.2.6.3. Usage
The run_slm_sft.sh script launches SLM supervised fine-tuning using a specified preset and dataset.
$ cd /opt/pfn/pfcomp/codegen/MLSDK/examples/slm_sft
$ ./run_slm_sft.sh [qwen|swal|swal-small] <dataset>
Parameters:
Preset: Select one of the following training presets:
qwen: Fine-tune the Qwen2.5-1.5B model using predefined training parameters.swal: Fine-tune the TinySwallow-1.5B model using predefined training parameters.swal-small: Fine-tune the TinySwallow-1.5B model with a reduced hidden size and limited optimizations for faster training.
Dataset: Path to a dataset JSON file used for fine-tuning. Two sample datasets are provided with the example scripts.
/opt/pfn/pfcomp/codegen/MLSDK/examples/datasets/tanuki.json/opt/pfn/pfcomp/codegen/MLSDK/examples/datasets/bushi.json
7.2.6.4. Sample Datasets
1[
2 [
3 {
4 "role": "user",
5 "content": "4÷2+3×2を計算してください。計算の順序(かけ算やわり算を先にするなど)に注意してください。"
6 },
7 {
8 "role": "assistant",
9 "content": "えっと 4÷2は 2ですね それから 3×2は 6ですから 2+6で 8ですね わかりました"
10 }
11 ],
12 [
13 {
14 "role": "user",
15 "content": "ある数に7を足して2倍したら27になりました。元の数を求めてください。"
16 },
17 {
18 "role": "assistant",
19 "content": "わかりました。その もんだい、いっしょに かんがえましょう\n\nたとえば、もとの かずを 「x」と するですね。そこに 7を たして、さらに に倍したら 27に なると いうことですね\n\nだから 「x+7」を に倍した けいさんを かけないと いけないですね\n\n(x+7) × 2 = 27\n\nと かけるですね\n\nこれを といていけば もとの かずが わかりますね\n\nまず、に倍を わるために 両はんに 2を わってみましょうか\n\nx+7 = 27 ÷ 2 = 13 5/2\n\nいま 13 5/2 は 13.5と いえるですね\n\nつぎに、7を ひいてみます\n\n13.5 - 7 = 6.5\n\nだから、もとの かずは 6.5 と いえますね\n\nたしかめ算も、てきに あってるか やってみましょうか\n\n6.5に 7を たすと 13.5、それを に倍すると 27に なるですね\n\nぜひ、してみてください\n\nなんだか、けいさん むずかしい ときも あるけど、たのしみながら きましょうね"
20 }
1[
2 [
3 {
4 "role": "user",
5 "content": "あいうえお"
6 },
7 {
8 "role": "assistant",
9 "content": "あいうえお、とな。なんとも軽やかに耳に響く音にござる。拙者、新右衛門と申す。今日からそなたとの縁が始まったこと、まこと喜ばしきことでござる。何か用向きがあれば、何なりと申すがよい。拙者、そなたの話に耳を傾けるを是といたす。"
10 }
11 ],
12 [
13 {
14 "role": "user",
15 "content": "。。。"
16 },
17 {
18 "role": "assistant",
19 "content": "了解いたした。拙者、新右衛門と申す。\n何か御用があれば、遠慮なく申されるがよろしかろう。\nそなたのお役に立てること、誠の喜びにござる。\nされば、何なりとお申し付けくだされ。\n(※以降、新右衛門として応答を続けます。)"
20 }
7.2.6.5. Scripts
1#!/bin/bash
2set -ex -o pipefail
3
4preset=$1
5dataset_json=$2
6codegen_output_dir=${3:-"/tmp/run_slm_sft"}
7
8#########################################################
9# Set up paths and environment variables
10#########################################################
11
12CURRENT_DIR=$(realpath $(dirname $0))
13VENVDIR=/tmp/run_slm_sft_gian_venv
14# Set Huggingface cache directory to avoid filling up the home directory
15export HF_HOME=${HF_HOME:-"/tmp/huggingface"}
16
17#########################################################
18# Set training parameters based on preset
19#########################################################
20#
21# NOTE: eloss_threshold in the presets are set according to the experiment result.
22# eloss after 40 steps for qwen and swal according to the experiment on 2026-02-11
23# were as follows.
24#
25# | | TANUKI.json | BUSHI.json |
26# |------|--------------------|--------------------|
27# | qwen | 4.276381492614746 | 3.3284881114959717 |
28# | swal | 4.3392558097839355 | 3.6840715408325195 |
29
30if [[ "$preset" == "qwen" ]]; then
31 # Same as sft-gian-qwen-pyac-mncore2_nightly CI
32 device="mncore2:auto"
33 model="qwen2.5-1.5b"
34 tloss_threshold="0.018174"
35 eloss_threshold="4.500000"
36 max_steps="40" # Set to -1 to use default max_steps
37 batch_size=32
38 n_hidden_layers=-1
39elif [[ "$preset" == "swal" ]]; then
40 # Same as sft-gian-swal-pyac-mncore2_nightly CI
41 device="mncore2:auto"
42 model="tiny-swallow-1.5b"
43 tloss_threshold="0.018174"
44 eloss_threshold="4.500000"
45 max_steps="40" # Set to -1 to use default max_steps
46 batch_size=32
47 n_hidden_layers=-1
48elif [[ "$preset" == "swal-small" ]]; then
49 # Same as sft-gian-swal-pyac-small-mncore2_pr CI
50 device="mncore2:auto"
51 model="tiny-swallow-1.5b"
52 model="tiny-swallow-1.5b"
53 tloss_threshold="12.758696"
54 eloss_threshold="10.933026"
55 max_steps="3" # Set to -1 to use default max_steps
56 batch_size=32
57 n_hidden_layers=2
58else
59 echo "invalid preset: $preset"
60 exit 1
61fi
62
63#########################################################
64# MLSDK configuration via environment variables based on preset
65#########################################################
66
67if [[ "$preset" == "swal-small" ]]; then
68 export CODEGEN_SA_STEPS=100
69 export CODEGEN_NUM_SA_THREADS=22
70 export CODEGEN_N_TRANSPOSE_THREADS=8
71 export CODEGEN_N_DEV_COPY_STREAMS_THREADS=8
72else
73 export CODEGEN_SA_STEPS=10000
74 export CODEGEN_NUM_SA_THREADS=10
75 export CODEGEN_N_TRANSPOSE_THREADS=27
76 export CODEGEN_N_DEV_COPY_STREAMS_THREADS=27
77fi
78
79export CODEGEN_N_TRANSPOSE_THREADS=${CODEGEN_N_TRANSPOSE_THREADS:-27}
80export CODEGEN_N_DEV_COPY_STREAMS_THREADS=${CODEGEN_N_DEV_COPY_STREAMS_THREADS:-27}
81export CODEGEN_SA_STEPS=${CODEGEN_SA_STEPS:-10000}
82export CODEGEN_NUM_SA_THREADS=${CODEGEN_NUM_SA_THREADS:-22}
83export CODEGEN_ENABLE_SET_PARTIAL_LOCATION=1
84export CODEGEN_GEMM_FORCE_CHANNEL_SPLIT=1
85export CODEGEN_OP_DEF=ChainerIndexAdd=IndexAddBcast
86export CODEGEN_SKIP_RESOLVE_NEGATIVE_INDICES=1
87export CODEGEN_TIME_SLICE_SCATTERED_INDEXING_BCAST=1
88export CODEGEN_LAYOUT_PLANNER_Z_HONOR_LAYOUT_SPEC=1
89export CODEGEN_MAX_TIME_SLICE=400
90export CODEGEN_IGNORE_LAYOUT_CHECK=1
91export CODEGEN_ALLOW_UNUSED_LAYOUT_SPEC=1
92export CODEGEN_USE_ADDR_FIRST_Z=1
93export CODEGEN_LAYOUT_PLANNER_Z=1
94export CODEGEN_ALARM=7200
95# qwen's embedding and lm_head share weight and they use equivalent but
96# different layout. The layout plan will be confused if eval sets the
97# same layout to both.
98# TODO(hamaji): Come up with a way to handle reused shared weights.
99export CODEGEN_IGNORE_REUSED_VALUE_LAYOUT=1
100export CODEGEN_DEFER_SIMPLIFY=ReplaceAttention,ReplaceAttentionGrad
101export CODEGEN_NODE_SIM_ALLOW_UNEXPECTED_FAIL=1
102export CODEGEN_FORCE_ATTENTION_GRAD_AFTER_FORWARD=1
103export CODEGEN_AUTO_RECOMPUTE_HACK_FOR_QWEN=1
104export CODEGEN_STOP_USING_GENERIC_INDEXING_GATHER_INDEX_ADD=1
105export CODEGEN_GEMM_FORCE_WEIGHT_ON_DRAM=1
106export CODEGEN_LPZ_SKIP_PROPAGATE_TIME=1
107export CODEGEN_OPS_ON_HOST=ChainerAdamW
108export MNCORE_USE_EXTERNAL_DATA_FORMAT=1
109export PFVM_DISABLE_CONSTANT_REUSE=1
110
111#########################################################
112# Set up python environment
113#########################################################
114
115if [[ ! -d ${VENVDIR} ]]; then
116 python3 -m venv --system-site-packages ${VENVDIR}
117 source ${VENVDIR}/bin/activate
118 pip3 install -r ${CURRENT_DIR}/requirements.txt
119else
120 source ${VENVDIR}/bin/activate
121fi
122CODEGEN_DIR=$(realpath ${CURRENT_DIR}/../../../)
123source "${CODEGEN_DIR}/build/codegen_pythonpath.sh"
124
125#########################################################
126# Run SLM SFT
127#########################################################
128
129mkdir -p ${codegen_output_dir}
130python3 $(realpath $(dirname $0))/slm_sft.py \
131 --model ${model} \
132 --device ${device} \
133 --batch_size ${batch_size} \
134 --n_hidden_layer ${n_hidden_layers} \
135 --max_steps ${max_steps} \
136 --tloss_threshold ${tloss_threshold} \
137 --eloss_threshold ${eloss_threshold} \
138 --run mlsdk_examples_slm_sft \
139 --codegen_output_dir ${codegen_output_dir} \
140 --dataset_json ${dataset_json}
1import argparse
2import copy
3import json
4import logging
5import math
6import os
7import random
8import uuid
9from dataclasses import dataclass
10from datetime import datetime, timezone
11from pathlib import Path
12from typing import Any, Callable, Literal, Mapping, Optional, Tuple, Union
13
14import torch
15from datasets import Dataset, DatasetDict
16from deepspeed.ops.adam import DeepSpeedCPUAdam
17from mlsdk import (
18 CacheOptions,
19 Context,
20 MNDevice,
21 TensorProxy,
22 set_tensor_name,
23 set_tensor_name_in_module,
24 storage,
25 trace_event,
26 trace_scope,
27)
28from torch.utils.data import DataLoader, RandomSampler
29from tqdm import tqdm
30from transformers import (
31 AutoModelForCausalLM,
32 AutoTokenizer,
33 PreTrainedModel,
34 PreTrainedTokenizerBase,
35 Qwen2TokenizerFast,
36 get_scheduler,
37 pipeline,
38)
39
40SHOW_DETAILED_INFO_ITER = 20
41VOCAB = 151936
42CHAN = 1536
43HEAD = 12
44
45
46@dataclass
47class TrainingConfig:
48 dataset_json: Path
49 model_name: str
50 sequence_length: int
51 n_steps: int
52 batch_size: int
53 n_hidden_layers: int
54 max_steps: int
55 learning_rate: float
56 output_dir: Path
57 enable_load_codegen_dir: bool
58 save_model_dir: Optional[Path]
59 device: str
60 dtype: str
61 run_name: Optional[str]
62 generate: Literal["always", "skip", "first_only", "last_only"]
63 distable_progress_bar: bool
64 train_log_path: Optional[str]
65 tloss_threshold: Optional[float]
66 eloss_threshold: Optional[float]
67 grad_accumulation_step: int = 1
68
69
70def gen_logger(name: Optional[str] = None) -> logging.Logger:
71 logging_env = "INFO"
72 loglevel = logging.getLevelName(logging_env)
73
74 fmt = (
75 "%(levelname)s %(asctime)s %(thread)d %(threadName)s "
76 "%(filename)s:%(lineno)d] %(message)s"
77 )
78 date_format = "%H:%M:%S"
79 formatter = logging.Formatter(fmt, date_format)
80
81 stream_handler = logging.StreamHandler()
82 stream_handler.setLevel(loglevel)
83 stream_handler.setFormatter(formatter)
84
85 logger = logging.getLogger(name)
86 logger.setLevel(loglevel)
87 logger.addHandler(stream_handler)
88 return logger
89
90
91_logger = gen_logger(__name__)
92
93
94def save_train_log( # noqa: CFQ002
95 epoch: int,
96 loss: float,
97 mean_token_accuracy: float,
98 learning_rate: float,
99 grad_norm: float,
100 num_tokens: int,
101 step_count: int,
102 max_steps: int,
103 save_path: str,
104) -> None:
105 _logger.info(f"save_train_log {epoch} {step_count}/{max_steps}")
106
107 timestamp = datetime.now(timezone.utc).isoformat()
108 save_data = {
109 "epoch": epoch,
110 "loss": loss,
111 "mean_token_accuracy": mean_token_accuracy,
112 "timestamp": timestamp,
113 "learning_rate": learning_rate,
114 "grad_norm": grad_norm,
115 "num_tokens": num_tokens,
116 "step_count": step_count,
117 "max_steps": max_steps,
118 }
119
120 with open(save_path, "a") as f:
121 f.write(json.dumps(save_data) + "\n")
122 f.flush()
123
124
125def get_dataloaders(
126 tokenizer: Qwen2TokenizerFast, conf: TrainingConfig
127) -> dict[str, DataLoader]:
128 return get_dataloaders_conversation_json(tokenizer, conf)
129
130
131def get_dataloaders_conversation_json( # noqa: CFQ001
132 tokenizer: Qwen2TokenizerFast, conf: TrainingConfig
133) -> dict[str, DataLoader]:
134 sequence_length = conf.sequence_length
135 batch_size = conf.batch_size
136 num_valid_samples = 1
137
138 if not hasattr(get_dataloaders, "_cache"):
139 get_dataloaders._cache = {}
140 if conf.dataset_json in get_dataloaders._cache:
141 data = get_dataloaders._cache[conf.dataset_json]
142 print(f"Using cached data for {conf.dataset_json}")
143 else:
144 with open(conf.dataset_json, "r", encoding="utf-8") as f:
145 data = json.load(f)
146 get_dataloaders._cache[conf.dataset_json] = data
147
148 instructions = []
149 outputs = []
150 for conversation in data:
151 for i in range(0, len(conversation), 2):
152 if (
153 i + 1 < len(conversation)
154 and conversation[i]["role"] == "user"
155 and conversation[i + 1]["role"] == "assistant"
156 ):
157 instructions.append(conversation[i]["content"])
158 outputs.append(conversation[i + 1]["content"])
159 full_dataset = Dataset.from_dict({"instruction": instructions, "output": outputs})
160 raw_datasets = DatasetDict({"full": full_dataset.shuffle(seed=42)})
161
162 def tokenize(element: dict[str, Any]) -> dict[str, list[list[int]]]:
163 all_input_ids = []
164 all_labels = []
165 assistant_marker_tokens = tokenizer.encode(
166 "<|im_start|>assistant\n", add_special_tokens=False
167 )
168 assert len(assistant_marker_tokens) == 3
169 for instruction, output in zip(element["instruction"], element["output"]):
170 conversation = [
171 {"role": "user", "content": instruction},
172 {"role": "assistant", "content": output},
173 ]
174 text = tokenizer.apply_chat_template(
175 conversation,
176 tokenize=False,
177 )
178 assert isinstance(text, str)
179 lines = text.splitlines()
180 if "system" in lines[0]:
181 lines = lines[2:]
182 text = "\n".join(lines)
183 assert "user" in lines[0], lines
184 input_ids = tokenizer.encode(text, add_special_tokens=False)
185 all_marker_positions = []
186 for i in range(len(input_ids) - len(assistant_marker_tokens) + 1):
187 if (
188 input_ids[i : i + len(assistant_marker_tokens)]
189 == assistant_marker_tokens
190 ):
191 all_marker_positions.append(i)
192 assert len(all_marker_positions) == 1
193 assistant_start_idx = all_marker_positions[0] + len(assistant_marker_tokens)
194
195 # User part and markers are -100 (mask)
196 labels = [
197 -100 if i < assistant_start_idx else token_id
198 for i, token_id in enumerate(input_ids)
199 ]
200 all_input_ids.extend(input_ids)
201 all_labels.extend(labels)
202 input_batch = []
203 labels_batch = []
204 for i in range(0, len(all_input_ids), sequence_length):
205 input_chunk = all_input_ids[i : i + sequence_length]
206 label_chunk = all_labels[i : i + sequence_length]
207 if len(input_chunk) < sequence_length:
208 padding_length = sequence_length - len(input_chunk)
209 input_chunk += [tokenizer.pad_token_id] * padding_length
210 label_chunk += [
211 -100
212 ] * padding_length # Padding tokens are masked with -100
213 input_batch.append(input_chunk)
214 labels_batch.append(label_chunk)
215
216 return {
217 "input_ids": input_batch,
218 "labels": labels_batch,
219 }
220
221 tokenized_full_dataset_dict = raw_datasets.map(
222 tokenize, batched=True, remove_columns=raw_datasets["full"].column_names
223 )
224 tokenized_full_dataset = tokenized_full_dataset_dict["full"]
225 assert len(tokenized_full_dataset) >= num_valid_samples + 1
226
227 valid_set = tokenized_full_dataset.select(range(num_valid_samples))
228 train_set = tokenized_full_dataset.select(
229 range(num_valid_samples, len(tokenized_full_dataset))
230 )
231
232 tokenized_datasets = DatasetDict({"train": train_set, "valid": valid_set})
233
234 _logger.info(f"{len(tokenized_datasets['train'])=}")
235 _logger.info(f"{len(tokenized_datasets['valid'])=}")
236 train_sampler = None
237 shuffle_train_loader = True
238 g = torch.Generator()
239 g.manual_seed(42)
240 if len(tokenized_datasets["train"]) < batch_size:
241 train_sampler = RandomSampler(
242 tokenized_datasets["train"],
243 replacement=True,
244 num_samples=batch_size,
245 generator=g,
246 )
247 shuffle_train_loader = False
248 # the shuffle argument cannot be used with the sampler
249
250 def seed_worker(worker_id):
251 worker_seed = torch.initial_seed() % 2**32
252 torch.manual_seed(worker_seed)
253 random.seed(worker_seed)
254
255 # To retain label, use a custom collator instead of DataCollatorForLanguageModeling
256 def custom_data_collator(examples):
257 input_ids = torch.stack([torch.tensor(ex["input_ids"]) for ex in examples])
258 labels = torch.stack([torch.tensor(ex["labels"]) for ex in examples])
259 attention_mask = (input_ids != tokenizer.pad_token_id).long()
260 return {
261 "input_ids": input_ids,
262 "labels": labels,
263 "attention_mask": attention_mask,
264 }
265
266 dataloaders = {
267 "train": DataLoader(
268 tokenized_datasets["train"],
269 shuffle=shuffle_train_loader,
270 sampler=train_sampler,
271 worker_init_fn=seed_worker,
272 generator=g,
273 collate_fn=custom_data_collator,
274 batch_size=batch_size,
275 drop_last=True,
276 ),
277 "valid": DataLoader(
278 tokenized_datasets["valid"],
279 shuffle=False,
280 collate_fn=custom_data_collator,
281 drop_last=True,
282 ),
283 }
284 _logger.info(f"{len(dataloaders['train'])=}")
285 _logger.info(f"{len(dataloaders['valid'])=}")
286 assert (
287 len(dataloaders["train"]) > 0
288 ), f"{len(dataloaders['train'])=} No training data"
289 assert len(dataloaders["valid"]) == num_valid_samples
290 return dataloaders
291
292
293def split_batch_for_py_gradient_accumulation(
294 batch: dict[str, torch.Tensor], grad_accumulation_step: int
295) -> list[dict[str, torch.Tensor]]:
296 batch_size = len(batch["input_ids"])
297 assert (
298 batch_size % grad_accumulation_step == 0
299 ), f"{batch_size=} {grad_accumulation_step=}"
300
301 batch_for_gradient_accumulation: list[dict[str, torch.Tensor]] = []
302 for i in range(grad_accumulation_step):
303 batch_for_gradient_accumulation.append(
304 {
305 "input_ids": batch["input_ids"][i::grad_accumulation_step],
306 "labels": batch["labels"][i::grad_accumulation_step],
307 "attention_mask": batch["attention_mask"][i::grad_accumulation_step],
308 }
309 )
310 return batch_for_gradient_accumulation
311
312
313def get_model(
314 model_name: str,
315 dtype: str,
316 device: str,
317 n_hidden_layers: int,
318) -> torch.nn.Module:
319 model = (
320 AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
321 .to(device)
322 .to(getattr(torch, dtype))
323 )
324 if n_hidden_layers > 0:
325 assert n_hidden_layers <= len(model.model.layers)
326 model.model.layers = model.model.layers[:n_hidden_layers]
327 _logger.info(
328 f"Reducing the number of layers from {len(model.model.layers)} to {n_hidden_layers} because the num_hidden_layers parameter was modified via args." # NOQA: B950
329 )
330
331 _logger.info(type(model))
332 _logger.info(model.config)
333 model_size = sum(t.numel() for t in model.parameters())
334 model_dtype_size: dict[torch.dtype, int] = {}
335 for t in model.parameters():
336 model_dtype_size[t.dtype] = model_dtype_size.get(t.dtype, 0) + t.numel()
337 _logger.info(f"{model_size / 1000 ** 2:.1f}M parameters: {model_dtype_size}")
338 return model
339
340
341def get_tokenizer(model_name: str) -> Qwen2TokenizerFast:
342 tokenizer = AutoTokenizer.from_pretrained(model_name)
343 assert isinstance(tokenizer, PreTrainedTokenizerBase), f"{type(tokenizer)=}"
344 assert isinstance(tokenizer, Qwen2TokenizerFast), f"{type(tokenizer)=}"
345 return tokenizer
346
347
348def get_optimizer(model: torch.nn.Module, lr: float) -> torch.optim.Optimizer:
349 weight_decay = 0.0
350 return DeepSpeedCPUAdam(
351 model.parameters(),
352 lr=lr,
353 weight_decay=weight_decay,
354 adamw_mode=True,
355 )
356
357
358def gen_layout_specs(vocab, chan, seqlen, head, bsize, out="/tmp"): # NOQA: CFQ001
359 embed_shape = [vocab, chan]
360 indices_shape = [bsize, seqlen]
361 indices_idx_add_shape = [bsize * seqlen]
362 feats_shape = [bsize, seqlen, chan]
363 feats_idx_add_shape = [bsize * seqlen, chan]
364
365 embed_gemm_layout = "((25_Time:1, 3:1536, 8_L2B:1, 16_MAB:1, 4:1, 4:4), (96:16, 4_W:1, 4_PE:1); B@[L1B])" # NOQA: B950
366 embed_idx_layout = "((75_Time:4, 8_L2B:1, 16_MAB:1, 4:1, 4:4), (4_Time:1, 24:16, 4_W:1, 4_PE:1); B@[L1B])" # NOQA: B950
367 feats_gemm_layout = (
368 "((), (8:3072, 8_L1B:1, 2_Time:1, 2:1536, 16:1), (96:16, 4_W:1, 4_PE:1))"
369 )
370 feats_gather_layout = (
371 "((), (8_L2B:1, 8_L1B:1, 64:1), (4_Time:1, 24:64, 4_W:1, 4_PE:1))"
372 )
373 feats_idx_add_layout = feats_gather_layout.replace("(), ", "")
374 logits_layout = "((), (8:96, 8_L1B:1, 2_Time:25, 2:48, 16:1), (25_Time:1, 3:16, 8_L2B:1, 16_MAB:1, 4_W:1, 4_PE:1))" # NOQA: B950
375 indices_gather_layout = "((), (8_L2B:1, 8_L1B:1, 32:1, 2_W:1))"
376 indices_idx_add_layout = indices_gather_layout.replace("(), ", "")
377
378 gemm_layout_spec = [
379 {
380 "key": "embed_tokens",
381 "A": feats_gemm_layout,
382 "BT": embed_gemm_layout,
383 "C": logits_layout,
384 }
385 ]
386
387 layout_spec = []
388 for trigger, op_type in [
389 ("SwitchInput", "Gather"),
390 ("SwitchInput", "ChainerIndexAdd"),
391 ("FixOutput", "ChainerIndexAdd"),
392 ]:
393 layout_spec.append(
394 {
395 "trigger": trigger,
396 "op_type": op_type,
397 "shape": embed_shape,
398 "layout": embed_idx_layout,
399 }
400 )
401
402 layout_spec.append(
403 {
404 "trigger": "SwitchInput",
405 "op_type": "Gather",
406 "shape": indices_shape,
407 "layout": indices_gather_layout,
408 }
409 )
410 layout_spec.append(
411 {
412 "trigger": "SwitchInput",
413 "op_type": "ChainerIndexAdd",
414 "shape": indices_idx_add_shape,
415 "layout": indices_idx_add_layout,
416 }
417 )
418
419 layout_spec.append(
420 {
421 "trigger": "FixOutput",
422 "op_type": "Gather",
423 "shape": feats_shape,
424 "layout": feats_gather_layout,
425 }
426 )
427 layout_spec.append(
428 {
429 "trigger": "SwitchInput",
430 "op_type": "ChainerIndexAdd",
431 "shape": feats_idx_add_shape,
432 "layout": feats_idx_add_layout,
433 }
434 )
435
436 # For gradient accumulation of weights with time slice.
437 for trigger in ["SwitchInput", "FixOutput"]:
438 layout_spec.append(
439 {
440 "trigger": trigger,
441 "op_type": "Add",
442 "shape": embed_shape,
443 "layout": embed_idx_layout,
444 }
445 )
446 for trigger in ["SwitchInput", "FixOutput"]:
447 layout_spec.append(
448 {
449 "trigger": trigger,
450 "op_type": "Add",
451 "shape": [8960, chan],
452 "layout": "((16_MAB:1, 5_Time:1, 7:16, 4:1, 4:4), (96:112, 4_W:1, 4_PE:1); B@[L1B,L2B])", # NOQA: B950
453 }
454 )
455 for trigger in ["SwitchInput", "FixOutput"]:
456 layout_spec.append(
457 {
458 "trigger": trigger,
459 "op_type": "Add",
460 "shape": [chan, 8960],
461 "layout": "((96:112, 4_W:1, 4_PE:1), (16_MAB:1, 5_Time:1, 7:16, 4:1, 4:4); B@[L1B,L2B])", # NOQA: B950
462 }
463 )
464
465 # All-gather at L2B and L1B before Expand in GQA.
466 layout_spec.append(
467 {
468 "trigger": "SwitchInput",
469 "op_type": "Expand",
470 "shape": [1, 2, 1, seqlen, chan // head],
471 "layout": "((), (2_Time:1), (), (16_MAB:1, 16:16, 4:1, 4:4), (8:256, 4_W:1, 4_PE:1); B@[L1B,L2B])", # NOQA: B950
472 }
473 )
474 layout_spec.append(
475 {
476 "trigger": "FixOutput",
477 "op_type": "Expand",
478 "shape": [1, 2, 6, seqlen, chan // head],
479 "layout": "((), (2_Time:6), (6_Time:1), (16_MAB:1, 16:16, 4:1, 4:4), (8:256, 4_W:1, 4_PE:1); B@[L1B,L2B])", # NOQA: B950
480 }
481 )
482
483 with open(os.path.join(out, "gemm_layout_spec.json"), "w") as f:
484 json.dump(gemm_layout_spec, f, indent=2)
485
486 with open(os.path.join(out, "layout_spec.json"), "w") as f:
487 json.dump(layout_spec, f, indent=2)
488
489 return os.path.join(out, "gemm_layout_spec.json"), os.path.join(
490 out, "layout_spec.json"
491 )
492
493
494def get_compile_options(conf: TrainingConfig) -> dict[str, Any]:
495 gemm_layout_spec, layout_spec = gen_layout_specs(
496 vocab=VOCAB, chan=CHAN, seqlen=conf.sequence_length, head=HEAD, bsize=1
497 ) # NOQA: CFQ001
498 compile_options = {
499 "gemm_layout_spec": gemm_layout_spec,
500 "layout_spec": layout_spec,
501 "scheduler": "auto_recompute_sa",
502 }
503 return compile_options
504
505
506def save_huggingface_format(
507 model: PreTrainedModel, tokenizer: PreTrainedTokenizerBase, save_directory: Path
508):
509 _logger.info(f"Saving model to {save_directory}")
510 model.save_pretrained(str(save_directory))
511 tokenizer.save_pretrained(str(save_directory))
512
513
514def generate(
515 model: torch.nn.Module,
516 tokenizer: Qwen2TokenizerFast,
517 device: str,
518 num_return_sequences: int = 1,
519) -> None:
520 model.eval()
521
522 def create_test_prompt(tokenizer: Qwen2TokenizerFast, user_instruction: str) -> str:
523 conversation = [
524 {"role": "user", "content": user_instruction},
525 ]
526 prompt = tokenizer.apply_chat_template(
527 conversation,
528 tokenize=False,
529 add_generation_prompt=True,
530 )
531 lines = prompt.splitlines()
532 if "system" in lines[0]:
533 lines = lines[2:]
534 prompt = "\n".join(lines)
535 assert "user" in lines[0]
536 return prompt + "\n"
537
538 with torch.no_grad():
539 pipe = pipeline(
540 "text-generation",
541 model=model,
542 tokenizer=tokenizer,
543 device=device,
544 max_new_tokens=32,
545 )
546 txt = [
547 create_test_prompt(tokenizer, "日本の首都は?"),
548 create_test_prompt(tokenizer, "田中、野球しようぜ。"),
549 create_test_prompt(tokenizer, "君はだれ?"),
550 create_test_prompt(tokenizer, "Hello! How are you?"),
551 create_test_prompt(tokenizer, "田中、一緒に海に行こうよ。"),
552 ]
553 results = pipe(txt, num_return_sequences=num_return_sequences)
554 for x in results:
555 for y in x:
556 _logger.info(y["generated_text"])
557 _logger.info("=" * 20)
558 model.train()
559
560
561def eval(
562 model: torch.nn.Module,
563 tokenizer: Qwen2TokenizerFast,
564 dataloaders: dict[str, DataLoader],
565 eval_step: Any,
566 device: str,
567) -> float:
568 model.eval()
569 with torch.no_grad():
570 eloss = Average()
571 for batch in tqdm(dataloaders["valid"], desc="eval"):
572 batch["input_ids"] = batch["input_ids"].to(device)
573 batch["labels"] = batch["labels"].to(device)
574 batch["attention_mask"] = batch["attention_mask"].to(device)
575 with torch.no_grad():
576 loss = eval_step(batch)["loss"]
577 eloss.update(loss)
578 _logger.info(f"eloss: {eloss.avg()}")
579 model.train()
580 return eloss.avg()
581
582
583def compile_for_py_grad_host_optimizer( # noqa: CFQ002, CFQ004
584 *,
585 conf: TrainingConfig,
586 context: Optional[Context],
587 model: torch.nn.Module,
588 tokenizer: Qwen2TokenizerFast,
589) -> Tuple[
590 Callable[[Mapping[str, torch.Tensor]], Mapping[str, torch.Tensor]],
591 Callable[[Mapping[str, torch.Tensor]], Mapping[str, torch.Tensor]],
592]: # noqa CFQ004
593 def calc_grads_and_loss(
594 inp: Mapping[str, torch.Tensor],
595 ) -> Mapping[str, torch.Tensor]:
596 assert inp["input_ids"].size() == inp["attention_mask"].size()
597 outputs = model(
598 input_ids=inp["input_ids"],
599 labels=inp["labels"],
600 attention_mask=inp["attention_mask"],
601 )
602 loss = outputs.loss
603 loss.backward()
604 return {"loss": loss}
605
606 def eval_step(inp: Mapping[str, torch.Tensor]) -> Mapping[str, torch.Tensor]:
607 outputs = model(
608 input_ids=inp["input_ids"],
609 labels=inp["labels"],
610 attention_mask=inp["attention_mask"],
611 )
612 loss = outputs.loss
613 return {"loss": loss}
614
615 set_tensor_name_in_module(model, "model")
616 for n, p in model.named_parameters():
617 context.register_param(p)
618
619 # Register grad tensor
620 p.grad = torch.nn.Parameter(torch.zeros_like(p))
621 set_tensor_name(p.grad, f"{n}_grad".replace(".", "@"))
622 context.register_param(p.grad)
623
624 train_codegen_dir = storage.path(
625 target=str(conf.output_dir / "codegen" / "train_step")
626 )
627 eval_codegen_dir = storage.path(
628 target=str(conf.output_dir / "codegen" / "eval_step")
629 )
630 if conf.enable_load_codegen_dir:
631 compiled_calc_grads_and_loss = context.load_codegen_dir(train_codegen_dir)
632 compiled_eval_step = context.load_codegen_dir(eval_codegen_dir)
633 return compiled_calc_grads_and_loss, compiled_eval_step
634
635 dataloaders: dict[str, DataLoader] = get_dataloaders(tokenizer, conf)
636 dat_train: DataLoader = dataloaders["train"]
637 it = iter(dat_train)
638
639 sample_input = next(it)
640
641 splitted_sample_input = split_batch_for_py_gradient_accumulation(
642 sample_input, conf.grad_accumulation_step
643 )[0]
644
645 _logger.info(f"{splitted_sample_input['input_ids'].size()=}")
646 _logger.info(f"{splitted_sample_input['labels'].size()=}")
647 _logger.info(f"{splitted_sample_input['attention_mask'].size()=}")
648
649 compile_options = get_compile_options(conf)
650
651 compiled_calc_grads_and_loss = context.compile(
652 calc_grads_and_loss,
653 splitted_sample_input,
654 train_codegen_dir,
655 options=compile_options,
656 cache_options=CacheOptions(str(conf.output_dir / "cache" / "train")),
657 )
658
659 compiled_eval_step = context.compile(
660 eval_step,
661 next(iter(dataloaders["valid"])),
662 eval_codegen_dir,
663 options=compile_options,
664 cache_options=CacheOptions(str(conf.output_dir / "cache" / "eval")),
665 )
666 return compiled_calc_grads_and_loss, compiled_eval_step
667
668
669class Average:
670 def __init__(self) -> None:
671 self.v = 0.0
672 self.n = 0
673
674 def update(self, v: Union[float, TensorProxy]) -> None:
675 if isinstance(v, TensorProxy):
676 v = v.cpu()
677 self.v += v
678 self.n += 1
679
680 def avg(self) -> float:
681 return self.v / self.n if self.n > 0 else torch.nan
682
683
684def run_with_py_gradient_accumulation( # noqa: CFQ001, CFQ002, CFQ004
685 conf: TrainingConfig,
686) -> None:
687 # To make the result reproducible.
688 torch.manual_seed(0)
689 # To show more digits in the log.
690 torch.set_printoptions(precision=10) # type: ignore
691
692 _logger.info(f"run_with_py_gradient_accumulation {conf.output_dir=}")
693 if conf.run_name is None:
694 conf.run_name = str(uuid.uuid4())
695 _logger.info(f"run name: {conf.run_name}")
696
697 context = Context(MNDevice(conf.device))
698 Context.switch_context(context)
699 tokenizer = get_tokenizer(conf.model_name)
700 model = get_model(
701 model_name=conf.model_name,
702 dtype=conf.dtype,
703 device="cpu", # Torch device is always CPU
704 n_hidden_layers=conf.n_hidden_layers,
705 )
706
707 # This function will register model parameters and their grads to the context,
708 # effectively moving the device from CPU to context's device (MN-Core).
709 calc_grads_and_loss, eval_step = compile_for_py_grad_host_optimizer(
710 conf=conf,
711 context=context,
712 model=model,
713 tokenizer=tokenizer,
714 )
715
716 dataloaders = get_dataloaders(tokenizer, conf)
717 # Create a copy of the model on CPU used for on-host optimization.
718 model_copy_on_cpu = copy.deepcopy(model).to("cpu")
719 optimizer = get_optimizer(model_copy_on_cpu, lr=conf.learning_rate)
720
721 if conf.n_steps == -1:
722 n_steps_per_epoch = len(dataloaders["train"])
723 _logger.info(f"{n_steps_per_epoch=}")
724 else:
725 n_steps_per_epoch = conf.n_steps
726
727 num_training_steps = conf.max_steps
728 n_epochs = math.ceil(conf.max_steps / n_steps_per_epoch)
729
730 lr_scheduler = get_scheduler(
731 "constant",
732 optimizer=optimizer,
733 num_warmup_steps=0,
734 num_training_steps=num_training_steps,
735 )
736 _logger.info(f"{num_training_steps=}")
737
738 if conf.generate == "first_only":
739 _logger.info("Generate is set to first_only. Generating before training...")
740 generate(model=model, tokenizer=tokenizer, device="cpu", num_return_sequences=1)
741 _logger.info("Generation before training done. Exit immediately.")
742 return
743
744 _logger.info(f"{n_steps_per_epoch=}")
745
746 step_count = 0
747 last_tloss = math.inf
748
749 for e in range(n_epochs):
750 _logger.info(f"EPOCH: {e} / {n_epochs}")
751 model.train()
752 bar = tqdm(range(n_steps_per_epoch), disable=conf.distable_progress_bar)
753 tloss = Average()
754 for i, batch in enumerate(dataloaders["train"]):
755 if i >= n_steps_per_epoch:
756 break
757
758 # Split batch for gradient accumulation
759 batches = split_batch_for_py_gradient_accumulation(
760 batch, conf.grad_accumulation_step
761 )
762 assert len(batches) == conf.grad_accumulation_step, len(batches)
763
764 batch_loss = torch.tensor(0.0, device="cpu")
765
766 # Accumulate gradients on the cpu (host)
767 for b in batches:
768 out = calc_grads_and_loss(b)
769 # This is not typo! The first `.cpu()` move the tensor in
770 # the codegen world to the torch world. The second `.cpu()`
771 # move the tensor from GPU or CPU to CPU.
772 loss = out["loss"].cpu().cpu()
773 batch_loss += loss
774 _logger.info(f"mini batch {loss=}")
775 del out, loss
776 del batches, batch
777 batch_loss /= conf.grad_accumulation_step
778 tloss.update(batch_loss)
779
780 if (e == 0 and i < SHOW_DETAILED_INFO_ITER) or i % 100 == 0:
781 _logger.info(f"{e=}, {i=}, {batch_loss=} {lr_scheduler.get_last_lr()=}")
782
783 # Fetch accumulated gradients from the device
784 context.synchronize()
785
786 # Copy grads to model on the host
787 grad_dict: dict[str, torch.Tensor] = {}
788 for k, v in model.named_parameters():
789 assert v.grad is not None
790 grad_dict[k] = v.grad.cpu()
791 for k, v in model_copy_on_cpu.named_parameters():
792 v.grad = grad_dict[k]
793
794 # Run optimizer on the host
795 with torch.no_grad():
796 with trace_event("optimizer"):
797 optimizer.step()
798 optimizer.zero_grad()
799
800 with trace_event("HtoD"): # Host to Device
801 with torch.no_grad():
802 # asynchronously copy model parameters to the device
803 for k, v in model.named_parameters():
804 context.get_registered_value_proxy(v).load_from(
805 model_copy_on_cpu.state_dict()[k], clone=False
806 )
807 assert v.grad is not None
808 context.get_registered_value_proxy(v.grad).load_from(
809 v.grad.zero_(), clone=False
810 )
811 # copy model_on_cpu parameters to the model
812 for k, v in model.named_parameters():
813 v.copy_(model_copy_on_cpu.state_dict()[k])
814 assert v.grad is not None
815 # Note: We cannot clear grads in this way. This clear grads
816 # forever.
817 # p.grad = torch.nn.Parameter(torch.zero_like(p))
818 if context is None:
819 v.grad.zero_()
820
821 last_tloss = tloss.avg()
822 lr_scheduler.step() # do lr_scheduler.step after saving
823 bar.set_description(f"epoch: {e}, tloss: {last_tloss}")
824 bar.update(1)
825 if conf.train_log_path is not None:
826 save_train_log(
827 epoch=e,
828 loss=batch_loss.item(),
829 mean_token_accuracy=0,
830 learning_rate=lr_scheduler.get_last_lr(),
831 grad_norm=0,
832 num_tokens=0,
833 step_count=step_count,
834 max_steps=conf.max_steps,
835 save_path=conf.train_log_path,
836 )
837
838 step_count += 1
839 _logger.info(f"{step_count=}")
840
841 if step_count >= conf.max_steps:
842 break
843
844 eloss = eval(model, tokenizer, dataloaders, eval_step, device="cpu")
845 if e == n_epochs - 1 and conf.eloss_threshold is not None:
846 assert (
847 eloss <= conf.eloss_threshold
848 ), f"eloss {eloss} is greater than threshold {conf.eloss_threshold}"
849
850 if (conf.generate == "always") or (
851 (conf.generate == "last_only") and (e == n_epochs - 1)
852 ):
853 with torch.no_grad():
854 model.eval()
855 generate(model=model, tokenizer=tokenizer, device="cpu")
856 model.train()
857
858 context.synchronize()
859 if step_count >= conf.max_steps:
860 break
861 if conf.tloss_threshold is not None:
862 _logger.info(
863 f"last tloss: {last_tloss}, tloss_threshold: {conf.tloss_threshold}"
864 )
865 assert last_tloss <= conf.tloss_threshold
866 if conf.save_model_dir:
867 save_huggingface_format(model, tokenizer, conf.save_model_dir)
868
869
870def main() -> None: # noqa: CFQ001
871 argparser = argparse.ArgumentParser()
872
873 argparser.add_argument(
874 "--dataset_json",
875 type=Path,
876 help="Path to the conversation dataset in JSON format.",
877 )
878 argparser.add_argument(
879 "--model",
880 type=str,
881 default="tiny-swallow-1.5b",
882 help="Model name to use for training. Short names: qwen2.5-1.5b, tiny-swallow-1.5b",
883 )
884 argparser.add_argument("--sequence_length", type=int, default=4096)
885 argparser.add_argument("--n_steps", type=int, default=-1)
886 argparser.add_argument("--max_steps", type=int, default=40)
887 argparser.add_argument("--batch_size", type=int, default=32)
888 argparser.add_argument("--learning_rate", type=float, default=3e-5)
889 argparser.add_argument("--n_hidden_layers", type=int, default=-1)
890 argparser.add_argument(
891 "--codegen_output_dir", type=Path, default=Path("/tmp/slm_sft_gian_output")
892 )
893 argparser.add_argument("--enable_load_codegen_dir", action="store_true")
894 argparser.add_argument("--save_model_dir", type=Path, default=None)
895 argparser.add_argument("--device", type=str, default="mncore2:auto")
896 argparser.add_argument(
897 "--dtype", type=str, default="float", choices=["float", "bfloat16", "float16"]
898 )
899 argparser.add_argument("--run", type=str, default=None)
900 argparser.add_argument(
901 "--generate",
902 type=str,
903 default="last_only",
904 choices=[
905 "always",
906 "skip",
907 "first_only",
908 "last_only",
909 ],
910 )
911 argparser.add_argument("--tloss_threshold", type=float, default=None)
912 argparser.add_argument("--eloss_threshold", type=float, default=None)
913
914 argparser.add_argument("--disable_progress_bar", action="store_true")
915 argparser.add_argument(
916 "--perfetto_trace", type=str, default=None, help="perfetto trace file"
917 )
918 argparser.add_argument("--train_log_path", type=str, default=None)
919
920 args = argparser.parse_args()
921
922 if args.perfetto_trace:
923 perfetto_trace = args.perfetto_trace
924 else:
925 perfetto_trace = os.path.join(args.codegen_output_dir, "perfetto_trace.pb")
926
927 if args.model == "qwen2.5-1.5b":
928 args.model = "Qwen/Qwen2.5-1.5B-Instruct"
929 elif args.model == "tiny-swallow-1.5b":
930 args.model = "SakanaAI/TinySwallow-1.5B"
931
932 if not os.path.exists(args.dataset_json):
933 raise FileNotFoundError(
934 f"Dataset JSON file {args.dataset_json} does not exist."
935 )
936
937 if (args.save_model_dir is not None) and os.path.exists(args.save_model_dir):
938 _logger.error(f"Model output directory {args.save_model_dir} already exists.")
939 _logger.error("This may overwrite existing files.")
940 exit(1)
941
942 assert args.max_steps > 0, "max_steps must be greater than 0"
943 assert args.device.startswith("pfvm") or args.device.startswith(
944 "mncore"
945 ), "Only pfvm/mncore devices are supported."
946
947 conf = TrainingConfig(
948 dataset_json=args.dataset_json,
949 model_name=args.model,
950 sequence_length=args.sequence_length,
951 n_steps=args.n_steps,
952 max_steps=args.max_steps,
953 learning_rate=args.learning_rate,
954 batch_size=args.batch_size,
955 n_hidden_layers=args.n_hidden_layers,
956 output_dir=args.codegen_output_dir,
957 enable_load_codegen_dir=args.enable_load_codegen_dir,
958 save_model_dir=args.save_model_dir,
959 device=args.device,
960 dtype=args.dtype,
961 run_name=args.run,
962 generate=args.generate,
963 distable_progress_bar=args.disable_progress_bar,
964 tloss_threshold=args.tloss_threshold,
965 eloss_threshold=args.eloss_threshold,
966 grad_accumulation_step=args.batch_size,
967 train_log_path=args.train_log_path,
968 )
969
970 # Create trace directory if it does not exist
971 trace_dir = os.path.dirname(perfetto_trace)
972 if not os.path.exists(trace_dir):
973 os.makedirs(trace_dir)
974
975 with trace_scope(perfetto_trace):
976 run_with_py_gradient_accumulation(conf)
977
978
979if __name__ == "__main__":
980 main()