6.4.1. FX2ONNX Exporter
6.4.1.1. FX2ONNX について
FX2ONNX は、深層学習コンパイラ向けに新たに開発された内製 ONNX エクスポーターです。PyTorch のネイティブな計算グラフ表現である FX Graph を経由して ONNX へ変換するため、backward 処理や torch.Tensor の書き換え処理なども計算グラフとして表現できます。これにより、従来の ONNX エクスポーターよりも汎用的なユースケースに対応可能になり、最適化できる範囲が拡大されたことでより実行効率の良い学習や推論が行えるようになりました。
PFVM は、PyTorch のコアライブラリである ATen ライブラリを利用したバックエンドを実装しています。この実装を活用し、FX2ONNX から得られる FX Graph の情報を PFVM へ透過的に渡すことで、PFVM が提供する計算グラフ最適化機能を、以下の特長と合わせて提供できるようになりました。
全ての PyTorch function に対応
PyTorch の deterministic mode の実行結果との完全一致を保証するモードのサポート
実行結果の厳密な完全一致を保証しない、より高度な最適化もサポート予定
また、同一の ONNX エクスポーターインターフェースを MN-Core でも利用することができます。FX2ONNX がモデルを ONNX に変換する際に必要な制約は、従来の ONNX エクスポーターの制約よりも小さく、より幅広いユースケースに対して PFVM を利用できるようになりました。
6.4.1.2. Compile Target Limitations & Code Modification
FX2ONNX は関数のトレースによって計算グラフを構築するため、対象とできる関数にいくつかの制約があります。以下にあるような挙動が含まれる関数は FX2ONNX の制約のため、正しく ONNX にすることができません。
Python scalar の作成
Global Python object の使用
動的shape (将来的なサポートの予定あり)
関数スコープ外の変数への torch.Tensor の代入
可能であれば、正しい ONNX に変換できるようにコードの修正を行ってから、ONNX への変換を行ってください。コード修正ができない場合は、FX2ONNX による ONNX 変換ができないため、個別に相談してください。
6.4.1.2.1. Python scalar の作成
python scalar の作成は全て Context.compile() 実行時の RuntimeError として検出されます。
pattern 1.
以下のような操作は正しく ONNX に変換できません。
import torch
a = 0
def f(x: torch.Tensor) -> torch.Tensor:
a += x.item()
return x + a
FX2ONNX は torch.Tensor に関する操作のみを追跡するため、 x.item() のような python scalar を作成する操作は許可されていません。同様の操作を実現したい場合は、 a を torch.Tensor で表現する必要があります。
import torch
a = torch.zeros((), dtype=torch.long)
def f(x: torch.Tensor) -> torch.Tensor:
a.add_(x)
return x + a
pattern 2.
以下のような操作は正しく ONNX に変換できません。
import torch
def f(x: torch.Tensor) -> torch.Tensor:
if (x > 0).all():
y = x + 1
else:
y = x - 1
return y
torch.Tensor の値を元に条件分岐を行う際には、暗黙的に python scalar への変換が行われるため、FX2ONNX ではコンパイルできません。必要な場合は、 torch.where() を用いて書き換える必要があります。
import torch
def f(x: torch.Tensor) -> torch.Tensor:
one = torch.where(
(x > 0).all(), torch.tensor(1.0, device=x.device), torch.tensor(-1.0, device=x.device)
)
y = x + one
return y
tips
assert 文を導入している場合も、基本的には python scalar への変換に該当することになります。コンパイル時には不必要になるため、次のような分岐を与えることでコンパイル時のみスキップすることができます。
if not torch.compiler._is_compiling_flag:
assert False
6.4.1.2.2. Global Python object の使用
global object に関する操作は、現時点ではエラーとして検出されません。また、検出することが技術的に困難なケースがあります。
pattern 1.
以下のような操作は、trace 実行時点での状態で ONNX に変換されます。
import torch
cond = False
def f(x: torch.Tensor) -> torch.Tensor:
if cond:
y = x + 1
else:
y = x - 1
return y
trace 時点と実行時点で、 cond の値が異なる場合は、意図しない挙動になります。
pattern 2.
以下のような操作は、trace 実行時点での状態で ONNX に変換されます。
import torch
a = 0
def f(x: torch.Tensor) -> torch.Tensor:
y = x + a # a: global int object
return y
a に関して追加の操作を行わない場合は、 a = 0 として trace が行われます。
pattern 3.
以下のような操作は正しく ONNX に変換できません。
import torch
a = 0
def f(x: torch.Tensor) -> torch.Tensor:
y = x + a # torch.add(x, 0)
a += 1
return y
FX2ONNX は torch.Tensor の操作のみ追跡するため、 a += 1 に関しては追跡できません。さらに、計算グラフは global object の a に依存しているため、意図しない計算グラフがエクスポートされます。このような操作を行いたい場合は、 a に関する操作を torch.Tensor で表現する必要があります。
import torch
a = torch.zeros(())
def f(x: torch.Tensor) -> torch.Tensor:
y = x + a
a.add_(1)
return y
以下のようなケースも正しく ONNX に変換できないですが、問題として認識できるようになるのに時間がかかったり気付けなかったりすることがあるので、特に注意が必要です。
import torch
a = 0
def f(x : torch.Tensor) -> torch.Tensor:
if a > 10:
y = x + 1
else:
y = x - 1
a += 1
return y
6.4.1.2.3. 動的 shape
動的 shape に関する操作は、FX2ONNX では現時点ではサポートしておらず、 Context.compile() 実行時のエラーとして検出されます。
pattern 1.
FX2ONNX による変換では全て静的 shape であることが想定されています。以下のようなコードは正しく ONNX に変換できません。
import torch
def f(x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
z = y.clone()
z[x > 0] = x[x > 0]
return z
bool mask による indexing は動的 shape になるため、サポートされません。動的 shape になる箇所を回避するような変更を行なってください。
import torch
def f(x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
z = torch.where(x > 0, x, y)
return z
どうしても動的 shape である必要性がある場合は、個別に相談してください。
6.4.1.2.4. 関数スコープ外の変数への torch.Tensor の代入
関数スコープ外の変数への torch.Tensor の代入は現時点ではエラーとして検出されません。trace 後に意図せず、 FakeTensor が代入されている object が発生することで確認できる場合があります。
pattern 1.
以下のようなコードをコンパイルした場合は意図通りに動きません。
import torch
a = None
def f(x: torch.Tensor) -> torch.Tensor:
global a
a = x + 1
return x
計算グラフ表現からは、関数スコープ外の変数への代入操作を検知することができません。関数スコープ外へ torch.Tensor の操作を行いたい場合は、以下のようにします。
import torch
a = torch.empty((), dtype=torch.long)
def f(x: torch.Tensor) -> torch.Tensor:
a.copy_(x + 1)
return x
関数スコープ外の torch.Tensor object に対する inplace 操作で表現することで、inplace 先の torch.Tensor も計算グラフ内で追跡できるようになります。
6.4.1.3. Policy for runtime compatibility
FX2ONNX と PFVM は、最適化された計算グラフの実行において、PyTorch を直接実行した場合と完全に一致する挙動をデフォルトで提供します。これは、 図 6.4 に示すように、PyTorch の呼び出し関数を計算グラフに透過的に渡すことで保証されています。
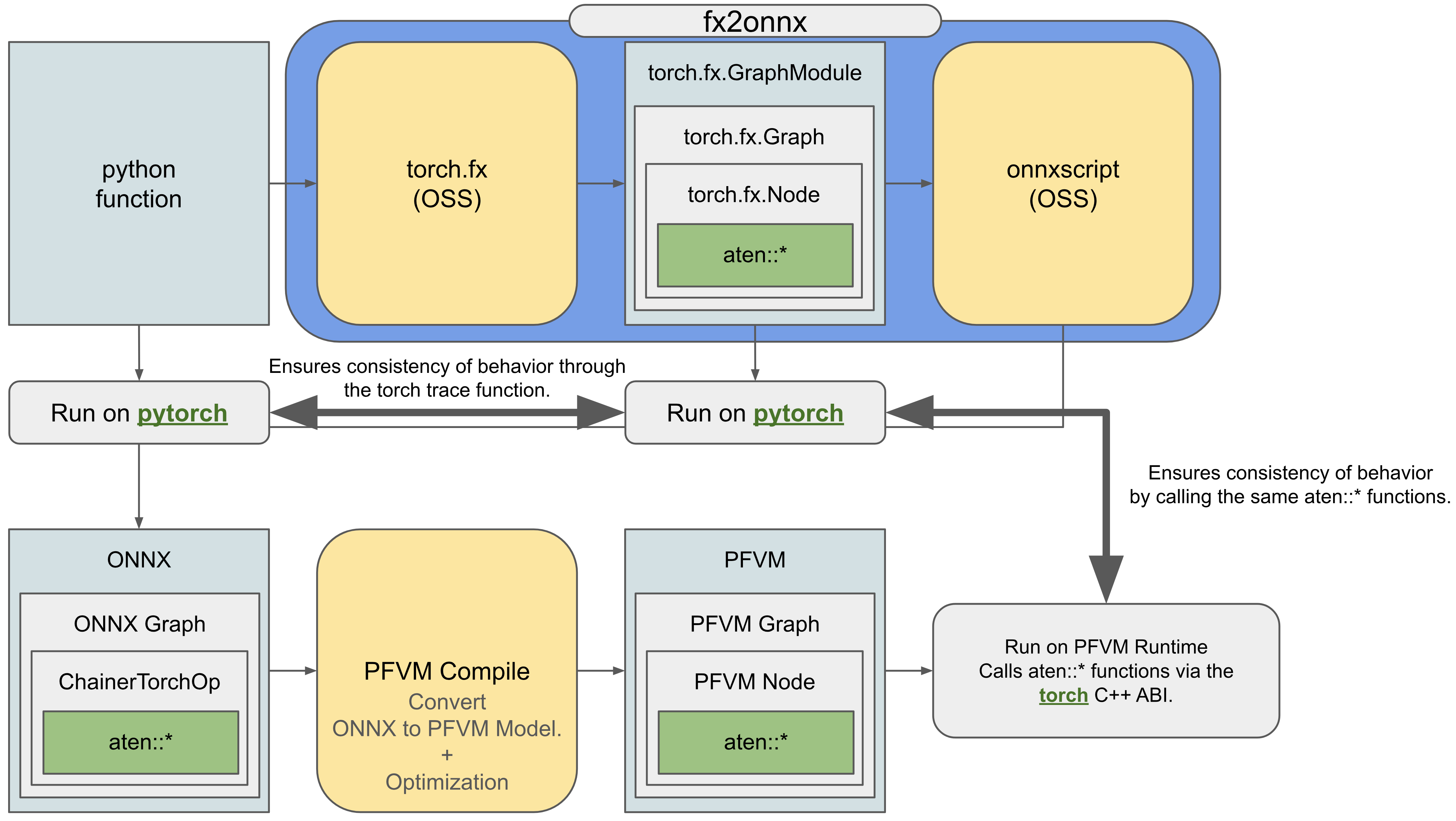
図 6.4 How to ensure the consistency of behavior between FX2ONNX+PFVM and PyTorch.
Compile Target Limitations & Code Modification の章で説明した制約を全て満たしており、 実行結果再現 のための deterministic mode の指定と seed の固定を行なった状態であれば、実行結果が完全一致することが広範なユースケースに渡って継続的に検証されています。また、PFVM では、挙動の完全一致の制約を外すことによって、さらに高度な最適化を提供することが可能です。