4. 発展的な機能
4.1. gpfn3-smiの機能
gpfn3-smi とは MN-Core 2 (コードネーム GPFN3) デバイスを監視・操作するためのコマンドラインユーティリティです。まず、MLSDK の原則として gpfn3-smi のコマンドは list を除いて使う必要はありません。デバイスの初期化処理は基本的に自動で行われます。ただし、意図しない理由でデバイスが不調になった場合や、高度なデバッグに有用なコマンドがあるため、ここではそれらについても紹介します。各種コマンドやその使用方法については、 --help オプションを指定することでも確認できますが、ここで紹介するもの以外は使用を推奨しません。
4.1.1. gpfn3-smi list
使用可能なデバイスのリストを表示します。
0: mnc2p27s0
1: mnc2p28s0
2: mnc2p42s0
3: mnc2p43s0
4: mnc2p171s0
5: mnc2p172s0
6: mnc2p187s0
7: mnc2p188s0
各デバイスの情報は (Device Index): (Deivce Name) のフォーマットで出力されます。Device Index は使用可能なデバイスに 0-based で番号を割り振ったもので、Device Name は計算ノードにおけるデバイスの名前です。PFCP 側の仕組みにより使用可能なデバイスは変動するため、Device Index と Device Name の対応は固定ではありません。mlsdk.MNDevice に使用するデバイスを指定する場合、Device Index (もしくは auto) を指定してください。
4.1.2. gpfn3-smi reset <device>
指定されたデバイスにリセットをかけます。
Usage: gpfn3-smi reset [options...] <device>
Examples:
gpfn3-smi reset 0
<device> には Device Index もしくは Device Name が指定できます。正常終了した場合、そのデバイスのリセットが完了しています。
警告
別のプログラムがロックしているデバイスをリセットした場合、そのプログラムの進捗が失われる可能性があります。
4.1.3. gpfn3-smi clear <device>
指定されたデバイス上の全てのメモリ (DRAM, Register, etc.) を指定された値で初期化します。
Clears all memory on the device. Mask registers are set to all ones regardless of the options.
Usage: gpfn3-smi clear [options...] <device>
Options:
-pattern uint
Fills the memory with the specified uint64 value instead of random bytes
-seed int
Seed value for random byte generation
-zero
Fills the memory with zeros instead of random bytes
Examples:
gpfn3-smi clear --seed 1234 0
gpfn3-smi clear --zero 0
gpfn3-smi clear --pattern 0x5555555555555555 0
大量のメモリ初期化が発生するため、実行完了に時間を要します。
4.2. コンパイルオプション
mlsdk.Context.compile() の options には、主に codegen の挙動に影響を与える Compile Options が指定できます。各オプションは options に指定する他、 option_json の引数にプリセットファイルとして渡すことも出来ます。同じオプションに異なる値が渡された場合、 options に直接指定したものが優先されます。例えば option_json と float_dtype を指定する場合、以下のような記述になります。
context.compile(
...
options={
"option_json": "/opt/pfn/pfcomp/codegen/preset_options/O1.json",
"float_dtype": "float",
},
)
Compile Options には、コマンドラインオプションのように指定するものと、環境変数として指定するものの2種類あります。options 経由では基本的に前者を指定できますが、 option_json に指定することで後者も指定可能です。ここからは Compile Options に指定可能な項目について説明します。
4.2.1. Preset Options
Compile Options の選択肢から適切なものを組み合わせた、ユーザーの状況に合わせて使い分けられる設定集です。MLSDK の環境では /opt/pfn/pfcomp/codegen/preset_options/ 以下にこれらの Preset Options があります。
O0.json: codegen のコンパイルが通り切ることを優先します。O1.json: O2 以降と同じスケジューラですが、最適化の設定は最も控えめです。O2.json: 焼きなまし法を活用したスケジューリングを行います。O3.json: O2 から探索範囲を拡大し、 L1Merge も活用します。O4.json: O3 から更に探索範囲を拡大します。debug.json: シンプルなスケジューラを用い、複雑な最適化は行わない設定です。
O0 から O4 にかけて最適化の度合いが高くなり、より最適化されたバイナリが得られますが、その分スケジューリングにかかる時間が長くなります。特に O2 以降は Node Simulation やその後の焼きなまし法にかかる時間が長くなるため、コンパイルが通るかのチェックには O1 以下をおすすめします。また、 Node Simulation の結果を mlsdk.CacheOptions を設定して再利用することもおすすめします。
debug に関しては、最適化をなるべく抑えることでコンパイル結果を調べやすくする設定のため、O0 や O1 よりもコンパイルの確実性は劣ります。そのため、普段の用途で用いることは想定されていません。
4.2.2. コマンドラインオプション
4.2.2.1. option_json
環境変数も含めたコンパイルオプションが記述された JSON ファイルの Path を受け取ります。JSON のフォーマットは以下の通りです。
{
"envs": {
"<CODEGEN_ENV_NAME>": <CODEGEN_ENV_VALUE>,
...
},
"args": [
"--<option_name>=<option_value>",
...
],
"name": <name>
}
envs: 有効な環境変数を記述できます。既に設定されている環境変数を指定した場合、option_json側の値は無視されます。args: 各オプションを順番通りに指定します。例えばfloat_dtypeを指定する場合、"--float_dtype=float"とします。また、option_jsonが指定されている場合は無視します (ネストした指定はできません)。name(optional) : 設定に名前をつけることができます。
また、 codegen_dir に生成される option.json は、 option_json で指定可能な JSON ファイルです。これを再度指定することによって、その codegen_dir が作られた時のコンパイルオプションを再現可能です。
4.2.2.2. float_dtype
torch.float32 型の Tensor に対し、 codegen がどの浮動小数点数型を割り当てるかを指定するオプションです。mlsdk.Context.compile() の options の説明も参照してください。
options={"float_dtype": "<value>"},
mixed: Uses half-precision for GEMM operations (in/out) and float otherwisehalf: Assign half-precision to all such tensorsfloat: Assign float-precision to all such tensorsdouble: Assign double-precision to all such tensors
ここで用いられる各演算精度については、 Dtype を参照してください。
4.2.2.3. layout_planner
Layout Planner を設定します。
options={"layout_planner": "<value>"},
lpz(default) : Uses Layout Planner Z, which is based onbidiorlegacywith improvementsbidi: Use bidirectional layout plannerlegacy: Use legacy layout planner
4.2.2.4. scheduler
Scheduler を設定します。
options={"scheduler": "<value>"},
always_from_dram: Always download data from DRAM before executing each op and upload the outputs of it after the execution.reuse_consecutive(default) : Similar toalways_from_dram, but utilizes existing data in SRAM output by the previous layer.spill_opt: Delay uploading data until SRAM becomes full.auto_recompute_sa: Anneal order of ops and SRAM-only values.
下にあるスケジューラほど高度な最適化を行いますが、その分完了に時間がかかります。
4.2.2.5. simulation_mode
Node Simulation を設定します。
options={"simulation_mode": "<value>"},
auto: Choose a suitablesimulation_modeaccording toscheduler.default: Simulate appropriate patterns of ConstrainAssignment.fast: Simulate certain patterns of ConstrainAssignment.best: Simulate so many patterns of ConstrainAssignment that some simulations may end in failure.full: Simulate all patterns of ConstrainAssignment regardless of any failures and duplications.fake: No simulation, just rough estimations. (Hence the fastest.)
シミュレーションする各パターンは Location やパラメータなどの組み合わせから生成されており、オペレータの実装者はそれぞれに対してコンパイルが成功するかどうかの期待値を設定します。高度な設定であるほど失敗しそうなパターンについてもシミュレーションを試みるため、失敗することもあります。その場合はそのパターンは使用されず、最終的に成功したパターンのみでスケジューリングを行います。ただし、一つも成功したパターンが存在しない場合、Node Simulation の段階でコンパイルを終了します。
4.2.2.6. sram_budget
スケジューラが利用可能な LM の割合を 0 から 1 (default) までで指定します。
options={"sram_budget": <float value>},
4.2.2.7. sa_expected_run_iters
焼きなまし法を使った最適化ループの回数を指定します。デフォルトの値は 0 で、これは十分に最適化されるまで制限なくループを回すことを意味しています。ただし、スケジューリングに時間をかけ過ぎないよう、適度な値を設定したほうがベターです。
options={"sa_expected_run_iters": <int value>},
4.2.2.8. out_onnx
MLSDK Pipeline and Backend Correspondence における Optimized ONNX を指定されたパスへ出力します。
options={"out_onnx": </path/to/compiled.onnx>},
4.2.2.9. layout_spec
指定されたJSONファイルを使用して Layout を設定します。
options={"layout_spec": </path/to/layout_spec.json>},
JSONファイル内の各エントリは以下のフィールドを含む必要があります:
trigger:SwitchInputまたはFixOutputのいずれかで、指定されたオペレータの入力または出力にレイアウトを適用するかを示します。op_type: レイアウトが適用されるオペレータタイプ(op_type)。shape: レイアウトが適用されるテンソルの形状。layout: メモリレイアウト仕様。
layout_spec.json の例:
[
{
"trigger": "SwitchInput",
"op_type": "Gather",
"shape": [151936, 1536],
"layout": "((75_Time:4, 8_L2B:1, 16_MAB:1, 4:1, 4:4), (4_Time:1, 24:16, 4_W:1, 4_PE:1); B@[L1B])"
},
{
"trigger": "FixOutput",
"op_type": "ChainerIndexAdd",
"shape": [151936, 1536],
"layout": "((75_Time:4, 8_L2B:1, 16_MAB:1, 4:1, 4:4), (4_Time:1, 24:16, 4_W:1, 4_PE:1); B@[L1B])"
}
]
4.2.2.10. gemm_layout_spec
指定されたJSONファイルを使用してGEMM用の Layout を設定します。
options={"gemm_layout_spec": </path/to/gemm_layout_spec.json>},
JSONファイル内の各エントリは以下のフィールドを含む必要があります:
key: GEMM演算の一意識別子。A: 行列Aのメモリレイアウト仕様。BT: 転置行列Bのメモリレイアウト仕様。C: 行列Cのメモリレイアウト仕様。
gemm_layout_spec.json の例:
[
{
"key": "embed_tokens",
"A": "((), (8:3072, 8_L1B:1, 2_Time:1, 2:1536, 16:1), (96:16, 4_W:1, 4_PE:1))",
"BT": "((25_Time:1, 3:1536, 8_L2B:1, 16_MAB:1, 4:1, 4:4), (96:16, 4_W:1, 4_PE:1); B@[L1B])",
"C": "((), (8:96, 8_L1B:1, 2_Time:25, 2:48, 16:1), (25_Time:1, 3:16, 8_L2B:1, 16_MAB:1, 4_W:1, 4_PE:1))"
}
]
4.2.3. 環境変数
4.2.3.1. CODEGEN_FIND_BEST_COMPILE_OPTIONS
利用可能なすべてのEmitストラテジーを試し、最適なものを見つけます。
4.2.3.2. CODEGEN_FIND_BETTER_COMPILE_OPTIONS
利用可能なEmitストラテジーから合理的な選択肢を試し、最適なものを見つけます。
4.2.3.3. CODEGEN_SCHEDULE_PP_BEAM_MAX_TURN
ノード再順序化のビームサーチにおける最大回転数。-1は制限なしを意味します。
4.2.3.4. CODEGEN_SCHEDULE_PP_BEAM_TURN_PRUNE_LIMIT
ノード再順序化のビームサーチにおいて改善なしで許容される最大回転数。
4.2.3.5. CODEGEN_SCHEDULE_PP_BEAM_WIDTH
ノード再順序化のビームサーチで考慮する候補の最大数。
4.2.3.6. CODEGEN_USE_MERGE
l1mergeを有効にします
4.2.3.7. CODEGEN_USE_PARALLEL_MERGE
l1mergeをO(log(N))の方法で並列化します
4.2.3.8. CODEGEN_SA_STEPS
スケジューラが使用する焼きなまし法最適化プロセスのステップ数(反復回数)を制御します。デフォルト値は1,000,000ステップです。値を大きくするとより良い最適化結果が得られる場合がありますが、コンパイル時間が増加します。これは特に``auto_recompute_sa``スケジューラを使用する際に関連します。
4.2.3.9. CODEGEN_NUM_SA_THREADS
焼きなまし法最適化で使用されるスレッド数を制御します。デフォルトは1です。値を大きくするとアニーリングプロセスを並列化できますが、より多くのメモリとCPUリソースが必要になる場合があります。
4.2.3.10. CODEGEN_N_TRANSPOSE_THREADS
データ転送中のデータステージング操作、特に転置操作に使用されるスレッド数を指定します。デフォルトは8スレッドです。複数の転置操作が並列化できる場合のみ、より高い値はデータ転送のスループットを向上させることができます。
4.2.3.11. CODEGEN_N_DEV_COPY_STREAMS_THREADS
デバイス-ホスト間およびホスト-デバイス間のデータ転送操作に使用される並列ストリーム数を制御します。デフォルトは8ストリームです。複数の転送が同時に発生可能な場合のみ、より高い値はデータ転送性能を向上させることができます。
4.2.3.12. CODEGEN_ENABLE_SET_PARTIAL_LOCATION
スケジューリングフェーズでResolveInconsistentDRAMInputにおいて部分的位置(LM/DRAM)の設定を有効にします。これはメモリ配置決定の最適化に役立ちますが、コンパイル時間に影響する場合があります。
4.2.3.13. CODEGEN_GEMM_FORCE_CHANNEL_SPLIT
GEMM演算で常にチャネル分割最適化を使用するよう強制します。これはデバッグ時やGEMM計算で特定のメモリレイアウトが必要な場合に有用です。
4.2.3.14. CODEGEN_OP_DEF
コードジェネレータのカスタムオペレーション定義を指定します。この高度なオプションにより、デフォルトのオペレーション動作を上書きしたり、カスタムオペレーション実装を追加したりできます。
使用例
CODEGEN_OP_DEF=Gather=GatherReduce,ChainerIndexAdd=IndexAddReduce
4.2.3.15. CODEGEN_SKIP_RESOLVE_NEGATIVE_INDICES
コンパイル時にテンソル演算での負のインデックスの解決をスキップします。これは負のインデックスが予期されない場合のデバッグや最適化オプションとして使用できます。
4.2.3.16. CODEGEN_TIME_SLICE_SCATTERED_INDEXING_BCAST
ブロードキャスト演算を伴う散在インデックスのタイムスライシング動作を制御します。これは複雑なインデックス演算でのメモリアクセスパターンの最適化方法に影響します。
4.2.3.17. CODEGEN_MAX_TIME_SLICE
コンパイル時に許可されるタイムスライスの最大数を設定します。デフォルトは256です。必要なタイムスライス数がこの制限を超えるとコンパイラは中止します。より複雑なタイムスライシングが必要なモデルでは増加させることができます。
4.2.3.18. CODEGEN_IGNORE_LAYOUT_CHECK
コンパイル時のレイアウト一貫性チェックを無効にします。このデバッグオプションは、コンパイル問題のトラブルシューティング時にレイアウト検証をバイパスするために使用できますが、不正な実行に繋がる可能性があります。
4.2.3.19. CODEGEN_ALLOW_UNUSED_LAYOUT_SPEC
レイアウト仕様が未使用のままでもコンパイルエラーを起こさないようにします。デバッグ時や、レイアウト仕様が提供されているがすべてが使用されることを期待していない場合に有用です。
4.2.3.20. CODEGEN_USE_ADDR_FIRST_Z
Layout Planner Zでアドレス優先最適化を有効にします。これはメモリアドレスが割り当てられる順序に影響し、メモリアクセスパターンと性能に影響を与える可能性があります。
4.2.3.21. CODEGEN_LAYOUT_PLANNER_Z
--layout_planner コマンドラインオプションを無視し、Layout Planner Zの使用を強制します。これはレイアウトプランナーの選択を上書きし、常にZバリアントを使用します。
4.2.3.22. CODEGEN_ALARM
正の値時に秒単位でアラームクロックを設定します。run_onnx_mncoreでのみ使用されます。タイムアウトが終了すると、コンパイルプロセスが中断されます。アラーム機能の詳細については``man alarm``を参照してください。
4.2.3.23. CODEGEN_IGNORE_REUSED_VALUE_LAYOUT
レイアウトプランニング時に再使用値のレイアウト制約を無視します。これはレイアウトの競合を解決するのに役立ちますが、メモリ効率と性能に影響を与える可能性があります。
4.2.3.24. CODEGEN_DEFER_SIMPLIFY
PFVM後パスに遅延させる簡略化関数のカンマ区切りリストを指定します。これにより、コンパイル時に特定のグラフ簡略化が適用されるタイミングを細かく調整できます。
4.2.3.25. CODEGEN_NODE_SIM_ALLOW_UNEXPECTED_FAIL
予想外の障害が発生してもノードシミュレーションを継続することを許可します。このデバッグオプションはノードシミュレーションの問題を特定するのに役立ちますが、最適以下の結果に繋がる可能性があります。
4.2.3.26. CODEGEN_FORCE_ATTENTION_GRAD_AFTER_FORWARD
アテンション勾配計算をフォワードパスの後にスケジュールするよう強制します。これはアテンションベースのモデルにおけるメモリ管理とスケジューリング最適化に役立ちます。
4.2.3.27. CODEGEN_AUTO_RECOMPUTE_HACK_FOR_QWEN
Qwenモデル向けの特定の自動再計算最適化を有効にします。このモデル固有の最適化は、Qwenベースのニューラルネットワークのメモリ使用量と性能を向上させることができます。
4.2.3.28. CODEGEN_STOP_USING_GENERIC_INDEXING_GATHER_INDEX_ADD
gather index add演算での汎用インデックシングの使用を無効にします。これは特定のユースケースにより適している可能性のある代替実装を強制的に使用するために使用できます。
4.2.3.29. CODEGEN_GEMM_FORCE_WEIGHT_ON_DRAM
GEMM演算の重みをローカルメモリ(LM)の代わりに常に DRAM に配置するよう強制します。これは大きな重み行列を扱う際のメモリ管理に有用です。
4.2.3.30. CODEGEN_LPZ_SKIP_PROPAGATE_TIME
Layout Planner Zでの時間伝播をスキップします。これはレイアウトプランニング時の時間依存関係の処理方法に影響し、スケジューリング決定に影響を与える可能性があります。
4.2.3.31. CODEGEN_OPS_ON_HOST
デバイスの代わりにホストで実行する演算タイプのカンマ区切りリストを指定します。例えば、 CODEGEN_OPS_ON_HOST=Exp,Log はMN-Coreの代わりにCPUで指数や対数演算を実行します。
4.2.3.32. CODEGEN_CONV_AGGRESSIVE_TIME_SLICING
畳み込みレイアウトの時分割を計算する際に、より積極的にLM予算を使用します。これにより、n_split を決定する前に、袖交換バッファと、必要に応じて畳み込み重みバッファ用の領域を予約します。
これによりタイムスライス数と実行時間が増える可能性がありますが、LM使用量のピークを抑えられる場合があります。デフォルトでは無効です。
4.2.3.33. CODEGEN_GN_AGGRESSIVE_TIME_SLICING
GroupNormレイアウトの時分割を計算する際に、分割前にバイアステンソル用の追加LM領域を予約することで、より積極的にLM予算を使用します。
これによりタイムスライス数と実行時間が増える可能性がありますが、LM使用量のピークを抑えられる場合があります。デフォルトでは無効です。
4.2.3.34. CODEGEN_SKIP_OPTIMIZER_FUSION
オプティマイザ融合パスを無効にします。有効にすると、MomentumやAdamなどのオプティマイザ演算子は、融合オプティマイザノードにまとめられず、そのまま残されます。
このオプションは、オプティマイザ融合に関するバグを回避するのに有用です。
4.2.3.35. CODEGEN_GENERIC_MOVE_CHUNK_SIZE
対象となるレイアウト切り替え演算でchunked generic moveを有効にし、チャンクサイズをlong word (LW) 単位で設定します。
値を小さくすると、move中のメモリ使用量のピークを抑えられますが、実行時間が増える可能性があります。各チャンクで処理される要素数は、CODEGEN_GENERIC_MOVE_CHUNK_SIZE にテンソルのデータ型における1 LWあたりの要素数を掛けたものです。-1 を指定するとこの最適化は無効化され、これがデフォルト値です。
chunked generic moveは、入力テンソルと出力テンソルのcore shapeが一致し、かつそれらのshapeにパディングがない場合にのみ使用されます。
4.2.3.36. MNCORE_USE_EXTERNAL_DATA_FORMAT
ONNXシリアライゼーションで外部データフォーマットの使用を有効にします。有効にすると、大きなテンソルはONNXモデルに埋め込まれる代わりに別ファイルに保存され、モデル読み込み時のメモリ使用量を削減します。
4.2.3.37. PFVM_DISABLE_CONSTANT_REUSE
PFVMパスでの定数再利用最適化を無効にします。設定すると、定数は計算グラフの異なる部分間で共有されなくなり、メモリ使用量が増加する可能性がありますが、デバッグを簡単にできます。
4.3. 直接codegen_dirを読み込む
キャッシュオプションを設定することでコンパイル結果を再利用できますが、再実行する際に適切な GPFNApp を選択するために関数のトレースを行うため、その分のコストがかかります。これに対して mlsdk.Context.load_codegen_dir() を使用して直接 codegen_dir を再利用することで、トレースのコストを回避することが出来ます。ただし、コンパイル対象の関数や入力テンソルの次元などが揃っていることが前提になるため、通常の開発用途には不向きです。
4.3.1. 使用例
Example: Load codegen_dir に使用例があります。
8# Load the previously compiled function
9loaded_add = context.load_codegen_dir(storage.path("/tmp/add_two_tensors"))
mlsdk.Context.compile() を呼ぶことなく直接 mlsdk.CompiledFunction が作成できます。
4.4. Codegen Dashboard
Codegen Dashboard は codegen_dir の内容をブラウザで確認するためのツールです。
注釈
codegen_dir 内の一部のファイルは Zstandard で圧縮され、 .zst の拡張子がついています。そのようなファイルは適切なビューワへ案内出来ないことがあり、その場合は先に展開する必要があります。
$ cd <codegen_dir> && zstd -d <filename>.zst
4.4.1. ダッシュボードを起動する
ワークスペースの Pod 内で
codegen-dashboard-externalをserveモードで起動
$ /opt/pfn/pfcomp/codegen/build/codegen-dashboard/codegen-dashboard-external serve <codegen_dir> --port 8327
指定したポートに対してローカルから
kubectl port-forward
$ kubectl port-forward pod/<pod-name> 8327:8327
Web ブラウザで
http://localhost:8327へアクセス
4.4.2. Summary
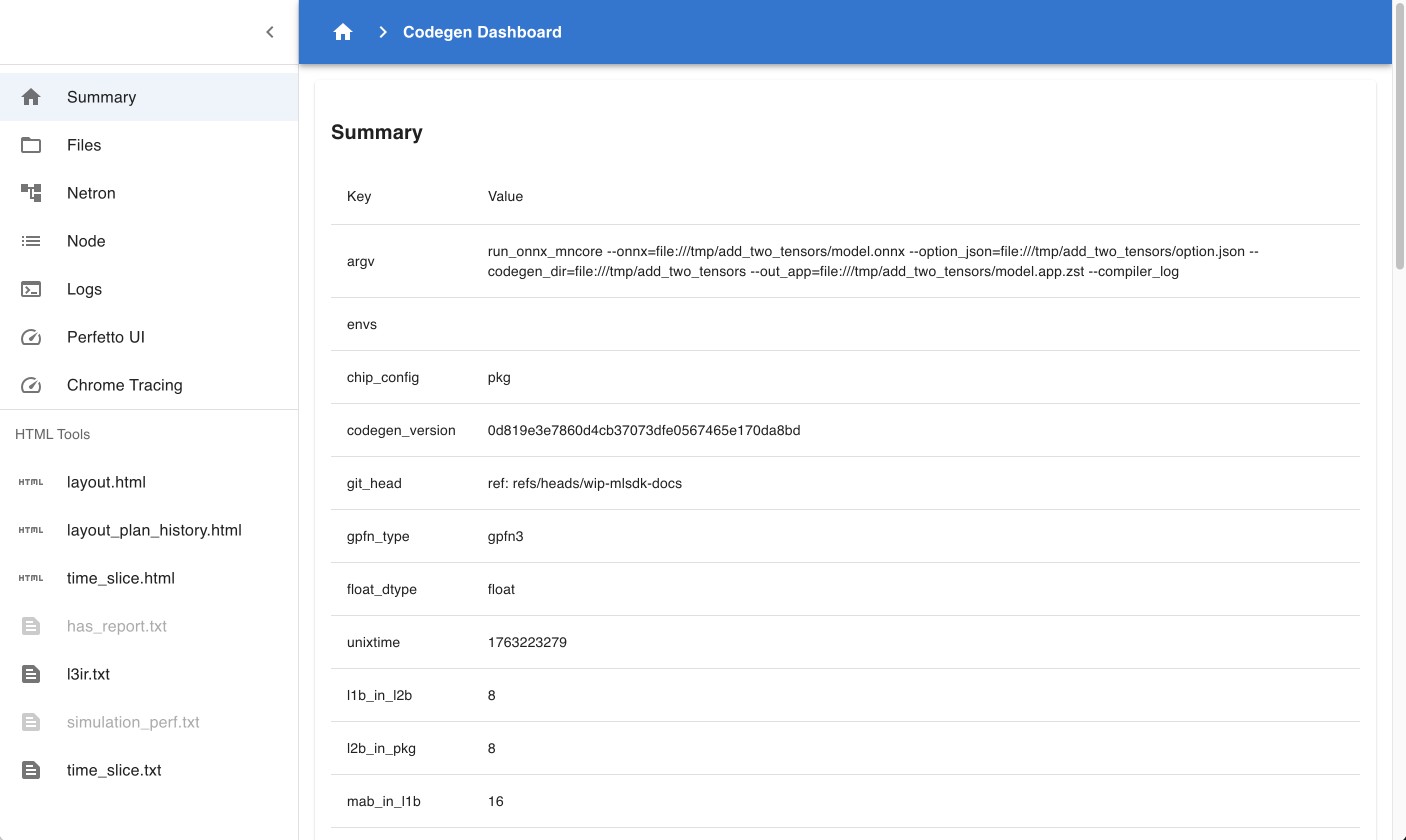
図 4.1 Codegen Dashboard: Summary
codegen_dir の内容をまとめたページです。
Summary : 実行したコマンドの内容や、ハードウェアの設定などをまとめています。中でも
flopsは計算グラフの計算回数を意味しており、大まかに規模を推測することができます。Compile Statuses : 各 Phase が成功したか否かと、かかった時間をまとめています。
Layers : MNGraph 中の各 Layer の情報をまとめています。
Perf Stats : Layers の内容を属性ごとに分け、それぞれにかかる時間などをまとめています。特に
ALLは計算全体にかかる時間を意味しており、 Compile Options による最適化の程度が確認できます。
4.4.3. Netron
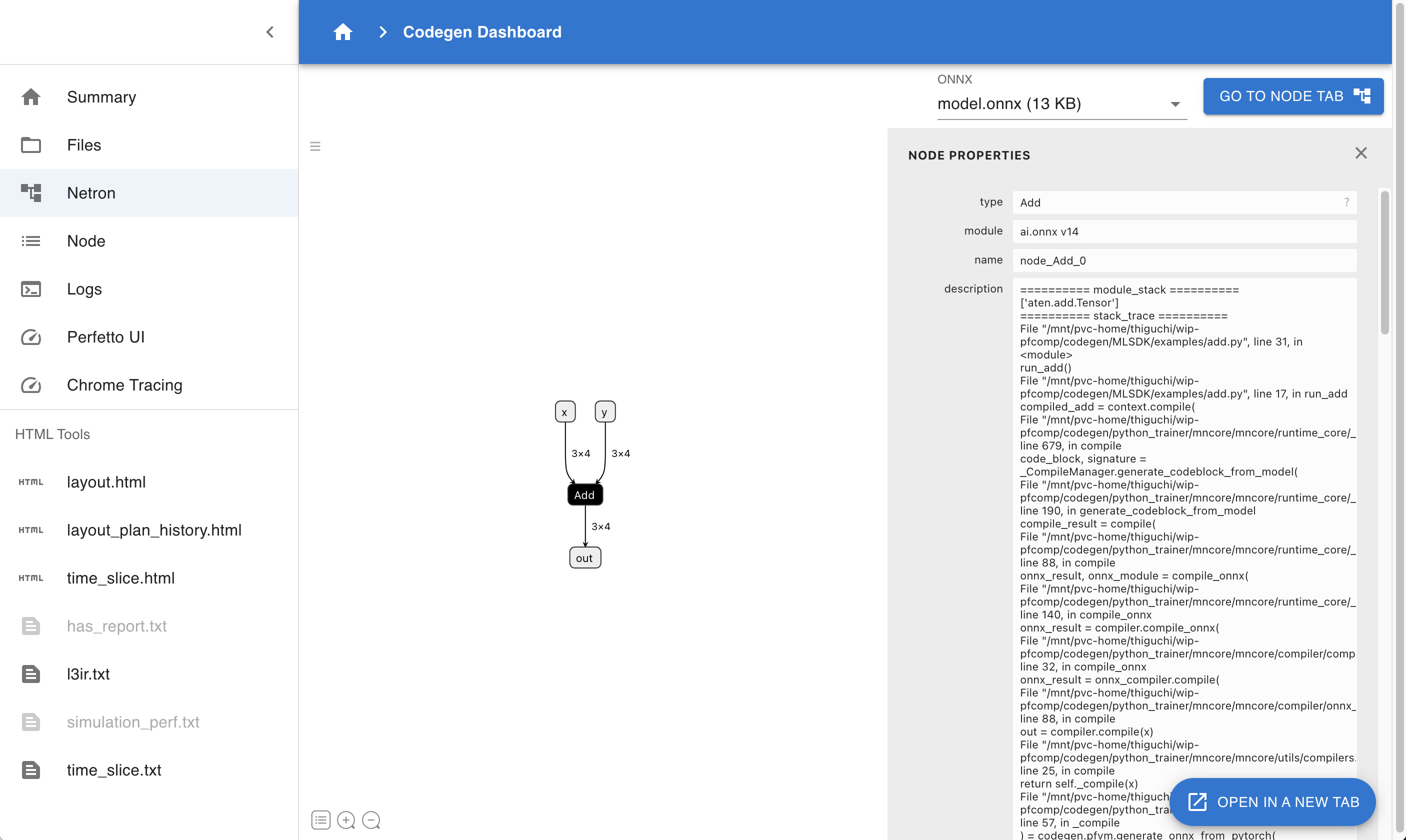
図 4.2 Codegen Dashboard: Netron
Netron で codegen_dir に含まれる ONNX ファイルを可視化できます。複数の ONNX ファイルが存在する場合、そこから確認するものを選べます。
4.4.4. Node
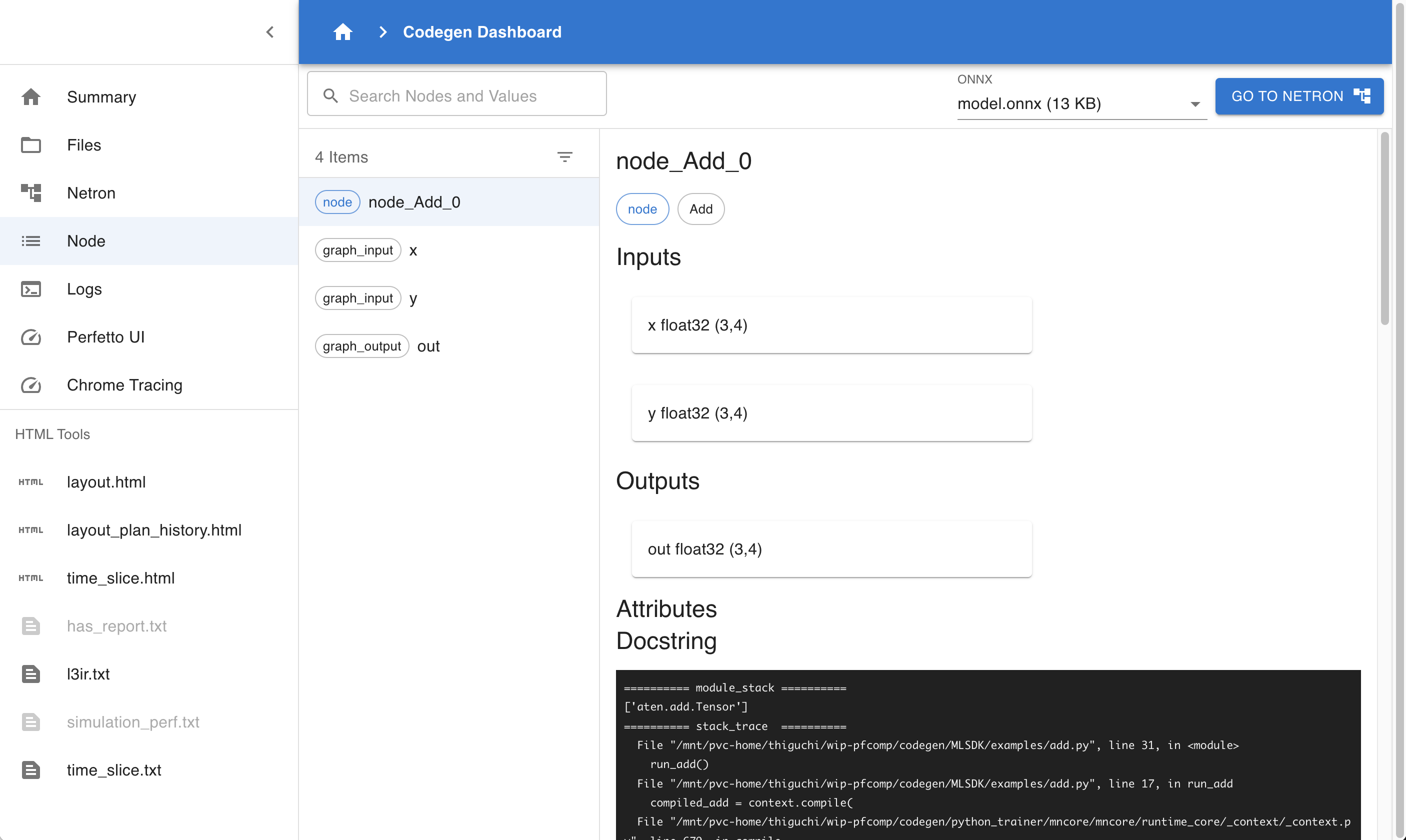
図 4.3 Codegen Dashboard: Node
Netron と同様に ONNX ファイルの内容を確認するページですが、グラフそのものを可視化するわけではないため、巨大なケースにおいても高速に動作します。
4.4.5. Logs
MLSDK のログ出力を確認できます。
CLOG.log: PFVM のログです。glog/codegen...: codegen のログです。マルチプロセスで動作した場合、それぞれが別ファイルにログ出力します。
4.4.6. Perfetto UI
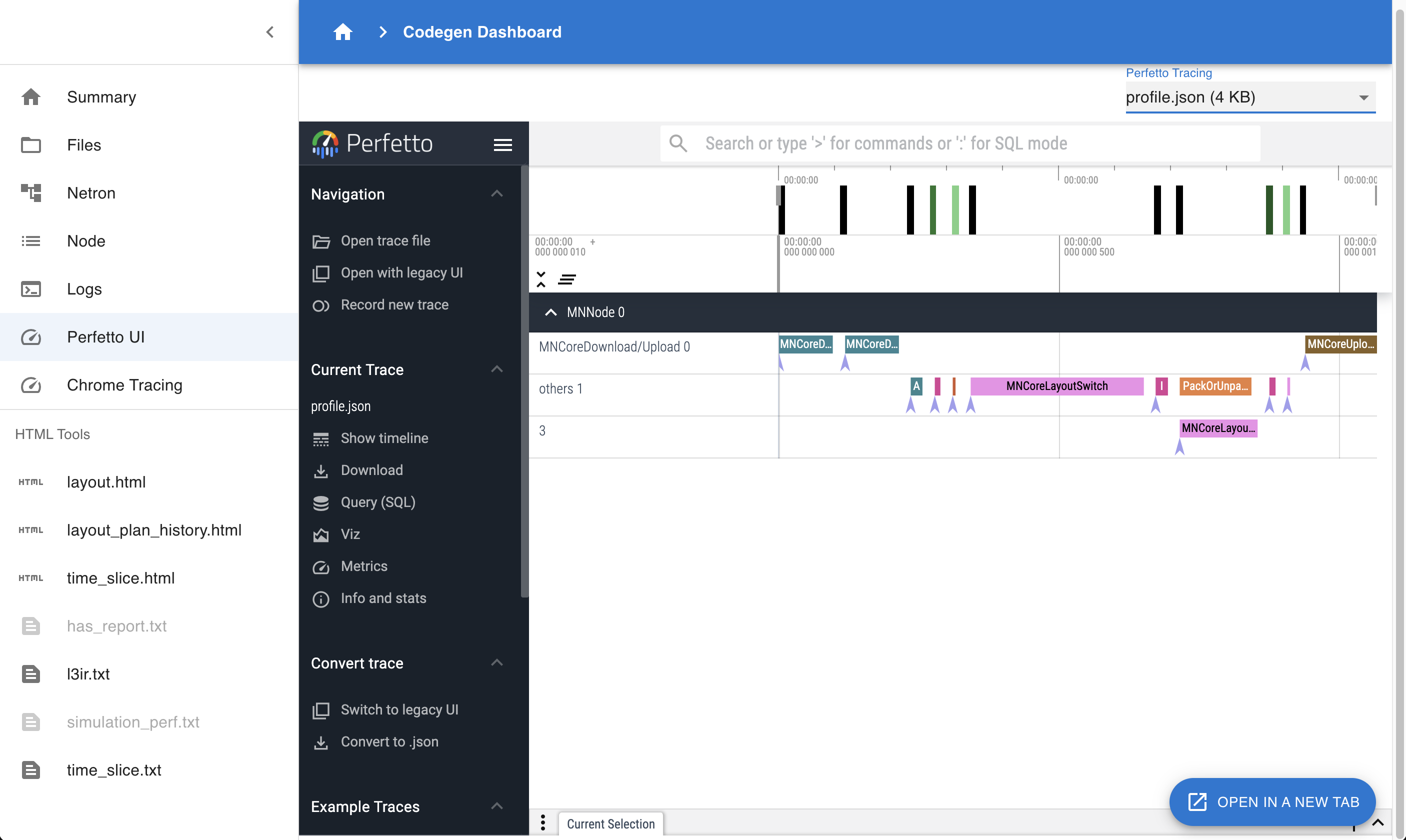
図 4.4 Codegen Dashboard: Perfetto UI
profile.json や trace.json などを Perfetto UI で可視化できます。デバイス上で各 Layer がいつどれくらいの時間をかけて実行されるか、などを調べるのに使います。
4.4.7. Chrome Tracing
図 4.5 Codegen Dashboard: Chrome Tracing
確認できる内容は基本的に Perfetto UI と同様ですが、こちらは Chrome Tracing の仕組みで可視化しています。
4.4.8. HTML Tools
layout.html: MNGraph に最終的に設定された Layout をまとめています。layout_plan_history.html: MNGraph に Layout がどのような経緯で設定されたかをまとめています。time_slice.html: Time-Slice によるグラフの分岐が起こる直前の Layout をまとめています。l3ir.txt: 計算スケジュールも含んだ MNGraph の表現です。time_slice.txt: Time-Slice によるグラフの分岐が起こる直前の、計算スケジュールも含んだ MNGraph の表現です。
4.5. TensorProxyを経由したデータ通信
mlsdk.TensorProxy は、 torch.Tensor がホスト上のテンソルとした時、それに対応するデバイス上のテンソルを表現するオブジェクトです。例えば mlsdk.CompiledFunction に入力として渡されたテンソルや、 mlsdk.Context.register_param() で登録されたパラメータは、対応する TensorProxy が作成され、それぞれの対応関係が mlsdk.Context 内部のレジストリに記録されます。
MLSDK におけるホストとデバイス間のデータ通信は TensorProxy を経由して行われます。はじめに で登場した mlsdk.TensorProxy.cpu() のように、デバイスからホストの通信 (D2H) は MLSDK のユーザーが明示的に指示しますが、ホストからデバイスの通信 (H2D) は暗黙的に行われます。これでも通常の使用では問題ありませんが、最適化の過程で H2D のタイミングを指示したい場合に使用できる API があります。
注釈
厳密には H2D の開始タイミングを指示する API のため、通信処理全体は非同期で行われます。H2D の完了を直接確認する API は現在提供しておりません。
4.5.1. TensorProxyオブジェクトを取得する
まず、H2D したい torch.Tensor に対応する TensorProxy を取得する必要があります。
CompiledFunction の入力
mlsdk.CompiledFunction.allocate_input_proxy() は CompiledFunction の入力に対応する TensorProxy を取得する API です。呼ばれたタイミングで入力を保持するためのバッファーがデバイス DRAM に確保され、対応するキーと TensorProxy が揃った Dict[str, TensorProxy] 型の値が取得できます。
Context に登録したテンソル
mlsdk.Context.get_registered_value_proxy() は mlsdk.Context.register_param() や mlsdk.Context.register_buffer() で Context に登録された TensorProxy を取得する API です。この場合、各 TensorProxy に対応するデバイス DRAM 領域は既に確保されているため、新しく DRAM の確保は行われません。
API の引数は register_param や register_buffer で登録された torch.Tensor で、対応する TensorProxy が取得できます。
4.5.2. TensorProxyオブジェクトへ値を書き込む
次に、取得した TensorProxy へ torch.Tensor を入力します。mlsdk.TensorProxy.load_from() は torch.Tensor 型の tensor と bool 型の clone フラグを受け取り、通信処理を開始します。
tensor
TensorProxy へ入力する値です。次元と型が同一であれば、必ずしも Context.compile へ渡したり Context へ登録した torch.Tensor と同じオブジェクトである必要はありません。
clone (default: True)
True:tensorの内容をコピーして転送キューに入れます。この方法はtensorに変更があっても問題ありませんが、コピーのコストがかかります。False:tensorへの参照を転送キューに入れます。この方法はコピーのコストがかかりませんが、途中にtensorに変更が発生した場合は未定義動作を引き起こします。tensorが一時オブジェクトの場合は問題ありません。
4.5.3. 使用例
Example: Explicitly Transferring Data Between Host And Device に使用例があります。
CompiledFunction の入力
33 input_proxies_allocated = compiled_infer.allocate_input_proxy()
34 input_proxies_allocated["x"].load_from(torch.ones(4, 4), clone=False)
ここで用意した input_proxies_allocated を後の compiled_infer の入力としています。
Context に登録したテンソル
36 for model_param in model.parameters():
37 model_param_proxy = context.get_registered_value_proxy(model_param)
38 model_param_proxy.load_from(model_param)
各 model_param は元々 compiled_infer の開始後に H2D しますが、先に通信を始めています。
4.5.4. 応用のヒント
モデルの学習ループを回すようなユースケースを考えた場合、基本的にこれらの1-4を繰り返すことで進行します。
データローダから入力データを取得
入力データを H2D
CompiledFunctionの実行出力データを D2H (同期)
重要なポイントとして、 H2D の際に MN-Core のレイアウトに合わせて転置処理が発生するため、ホストでの処理がボトルネックになることは多いです。このため、3と4の処理の間に1と2の処理を挟めると、ホストとデバイスの処理を上手くオーバーラップできます。