6.4.1. FX2ONNX Exporter
6.4.1.1. About FX2ONNX
FX2ONNX is a novel in-house-developed ONNX exporter specifically designed for deep learning compilers. It converts models to ONNX by FX Graph—PyTorch’s native computational graph representation—which enables the representation of backward operations and torch.Tensor rewriting processes as computational graphs. This approach allows FX2ONNX to handle a broader range of use cases compared to conventional ONNX exporters, while expanding the scope of optimizations to enable more efficient training and inference.
PFVM implements a backend using the ATen library, PyTorch’s core library. By utilizing this implementation and transparently passing FX Graph information from FX2ONNX to PFVM, we can now provide the following features along with PFVM’s computational graph optimization capabilities:
Support for all PyTorch functions
A mode that guarantees complete consistency with PyTorch’s deterministic execution results
Support for more advanced optimizations is also planned, which won’t guarantee exact, complete matches of execution results.
The same ONNX exporter interface can also be utilized with MN-Core. The constraints required for FX2ONNX to convert models to ONNX are more relaxed than those of conventional ONNX exporters, enabling PFVM to be used for a wider range of use cases.
6.4.1.2. Compile Target Limitations & Code Modification
Since FX2ONNX constructs computation graphs through function tracing, it imposes certain constraints on the types of functions it can handle. Functions containing any of the following behaviors cannot be properly converted to ONNX due to FX2ONNX’s limitations:
Creation of Python scalars
Global Python object usage
Dynamic shapes (though future support is planned)
Assignment of torch.Tensor values to variables outside function scope
If possible, modify the code to make it convertible to the correct ONNX format before conversion. If code modification isn’t feasible, FX2ONNX cannot perform the ONNX conversion, then please contact us individually.
6.4.1.2.1. Creation of Python scalars
Creating python scalars is detected as a RuntimeError during execution of Context.compile().
pattern 1.
The following operations cannot be correctly converted to ONNX:
import torch
a = 0
def f(x: torch.Tensor) -> torch.Tensor:
a += x.item()
return x + a
FX2ONNX only tracks operations involving torch.Tensor objects, so operations that create Python scalars like x.item() are not allowed.
To achieve similar functionality, a must be represented as a torch.Tensor.
import torch
a = torch.zeros((), dtype=torch.long)
def f(x: torch.Tensor) -> torch.Tensor:
a.add_(x)
return x + a
pattern 2.
The following operations cannot be correctly converted to ONNX:
import torch
def f(x: torch.Tensor) -> torch.Tensor:
if (x > 0).all():
y = x + 1
else:
y = x - 1
return y
When performing conditional branching based on torch.Tensor values, implicit conversion to Python scalars occurs, making the operation incompatible with FX2ONNX.
For such cases, you must rewrite the code using torch.where() instead.
import torch
def f(x: torch.Tensor) -> torch.Tensor:
one = torch.where(
(x > 0).all(), torch.tensor(1.0, device=x.device), torch.tensor(-1.0, device=x.device)
)
y = x + one
return y
tips
When using assert statements, this essentially corresponds to converting to Python scalars. Since these become unnecessary during compilation, you can skip them during compilation by providing the following conditional branch:
if not torch.compiler._is_compiling_flag:
assert False
6.4.1.2.2. Global Python object usage
Operations on global objects are currently not detected as errors, and some cases are technically difficult to detect.
pattern 1.
The following operations are converted to ONNX based on their state at the time of trace execution:
import torch
cond = False
def f(x: torch.Tensor) -> torch.Tensor:
if cond:
y = x + 1
else:
y = x - 1
return y
If the value of cond differs between tracing and execution phases, this may lead to unintended behavior.
pattern 2.
The following operations are converted to ONNX based on their state at the time of trace execution:
import torch
a = 0
def f(x: torch.Tensor) -> torch.Tensor:
y = x + a # a: global int object
return y
If no additional operations are performed with respect to a, it will be traced as a = 0.
pattern 3.
The following operations cannot be correctly converted to ONNX:
import torch
a = 0
def f(x: torch.Tensor) -> torch.Tensor:
y = x + a # torch.add(x, 0)
a += 1
return y
Since FX2ONNX only tracks operations on torch.Tensor objects, it cannot track operations like a += 1.
Additionally, because the computation graph depends on a global object a, it may export an unexpected computation graph.
To perform such operations, you need to represent operations involving a using torch.Tensor objects.
import torch
a = torch.zeros(())
def f(x: torch.Tensor) -> torch.Tensor:
y = x + a
a.add_(1)
return y
The following types of cases also cannot be correctly converted to ONNX format, yet they may sometimes take time to identify as issues or even go unnoticed, making them particularly problematic.
import torch
a = 0
def f(x : torch.Tensor) -> torch.Tensor:
if a > 10:
y = x + 1
else:
y = x - 1
a += 1
return y
6.4.1.2.3. Dynamic shapes
Operations involving dynamic shapes are not yet supported by FX2ONNX and will be detected as runtime errors during Context.compile() execution.
pattern 1.
The FX2ONNX conversion assumes all shapes are static. Code containing the following patterns cannot be correctly converted to ONNX:
import torch
def f(x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
z = y.clone()
z[x > 0] = x[x > 0]
return z
Indexing with a bool mask results in dynamic shapes, which is not supported. Please modify your code to avoid creating dynamic shapes.
import torch
def f(x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
z = torch.where(x > 0, x, y)
return z
If dynamic shape is absolutely necessary, please consult with us individually.
6.4.1.2.4. Assignment of torch.Tensor to variables outside function scope
Assignments of torch.Tensor to variables outside their function scope are currently not detected as errors.
This can sometimes be identified by observing that objects receive FakeTensor assignments unintentionally after tracing.
pattern 1.
Code like this won’t compile and won’t work as intended:
import torch
a = None
def f(x: torch.Tensor) -> torch.Tensor:
global a
a = x + 1
return x
The computation graph representation cannot detect assignment operations to variables outside function scopes. If you want to perform operations on torch.Tensor outside function scopes, use the following approach:
import torch
a = torch.empty((), dtype=torch.long)
def f(x: torch.Tensor) -> torch.Tensor:
a.copy_(x + 1)
return x
By representing in-place operations on torch.Tensor objects outside their function scope, allowing the destination torch.Tensor to be tracked within the computation graph.
6.4.1.3. Policy for runtime compatibility
FX2ONNX + PFVM provides default behavior that perfectly matches PyTorch’s execution when running optimized computation graphs. This is achieved by transparently passing PyTorch’s call functions into the computation graph (shown in Fig. 6.4).
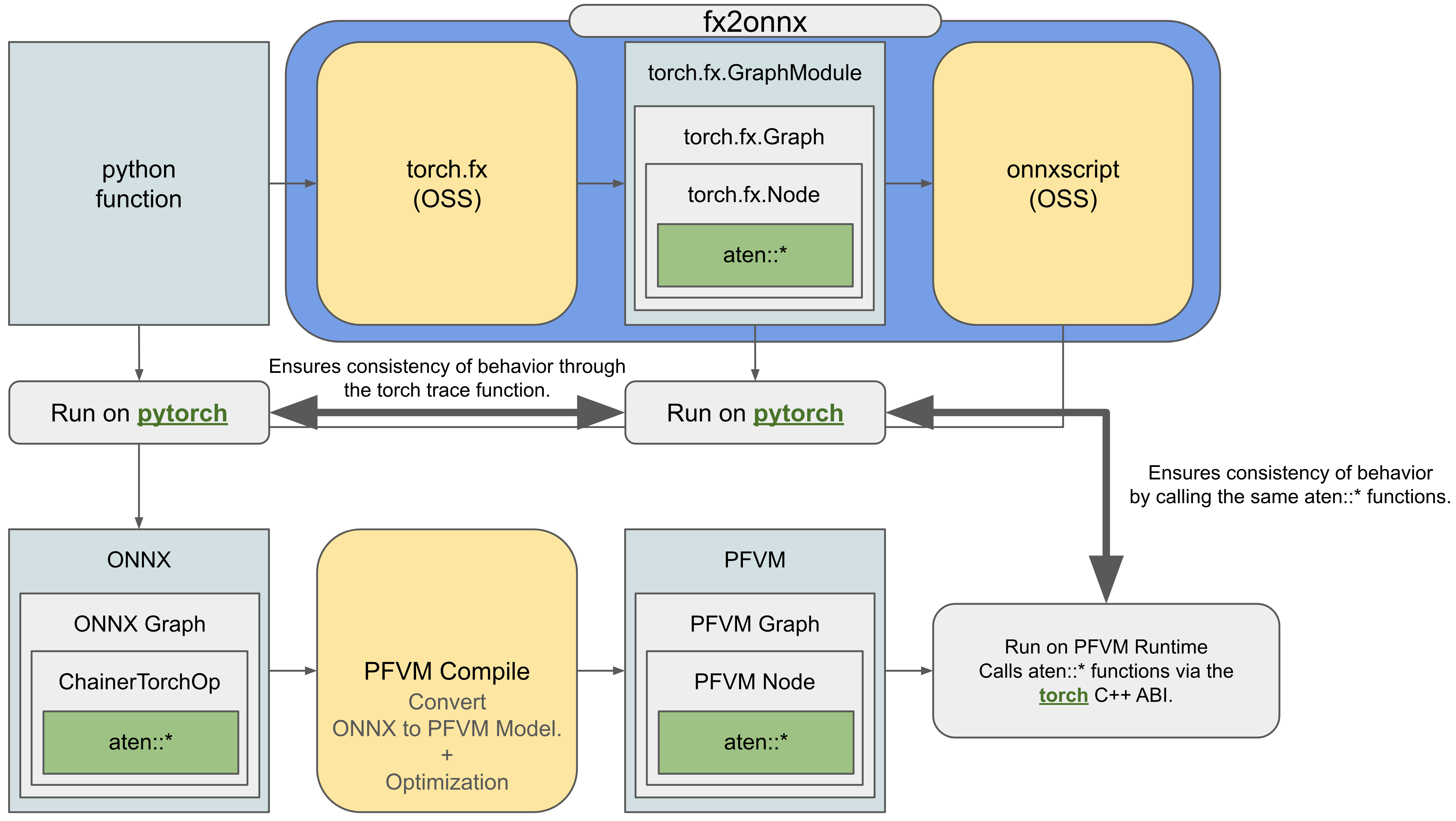
Fig. 6.4 How to ensure the consistency of behavior between FX2ONNX+PFVM and PyTorch.
We have thoroughly verified that execution results match exactly across a wide range of use cases when all constraints outlined in the Compile Target Limitations & Code Modification section are satisfied, including specifying deterministic mode and fixing the seed for result reproduction. Furthermore, PFVM can provide even more advanced optimizations by relaxing the requirement for exact behavioral consistency.